1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
| from uuid import uuid4
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor, LLMChainFilter, EmbeddingsFilter, \
DocumentCompressorPipeline
from langchain.text_splitter import CharacterTextSplitter
from langchain_community.chat_models import AzureChatOpenAI
from langchain_community.chat_models.baidu_qianfan_endpoint import QianfanChatEndpoint
from langchain_community.document_loaders.web_base import WebBaseLoader
from langchain_community.document_transformers import EmbeddingsRedundantFilter, LongContextReorder
from langchain_community.vectorstores.elasticsearch import ElasticsearchStore
import os
from langchain_community.embeddings import QianfanEmbeddingsEndpoint, HuggingFaceEmbeddings
from langchain_core.documents import Document
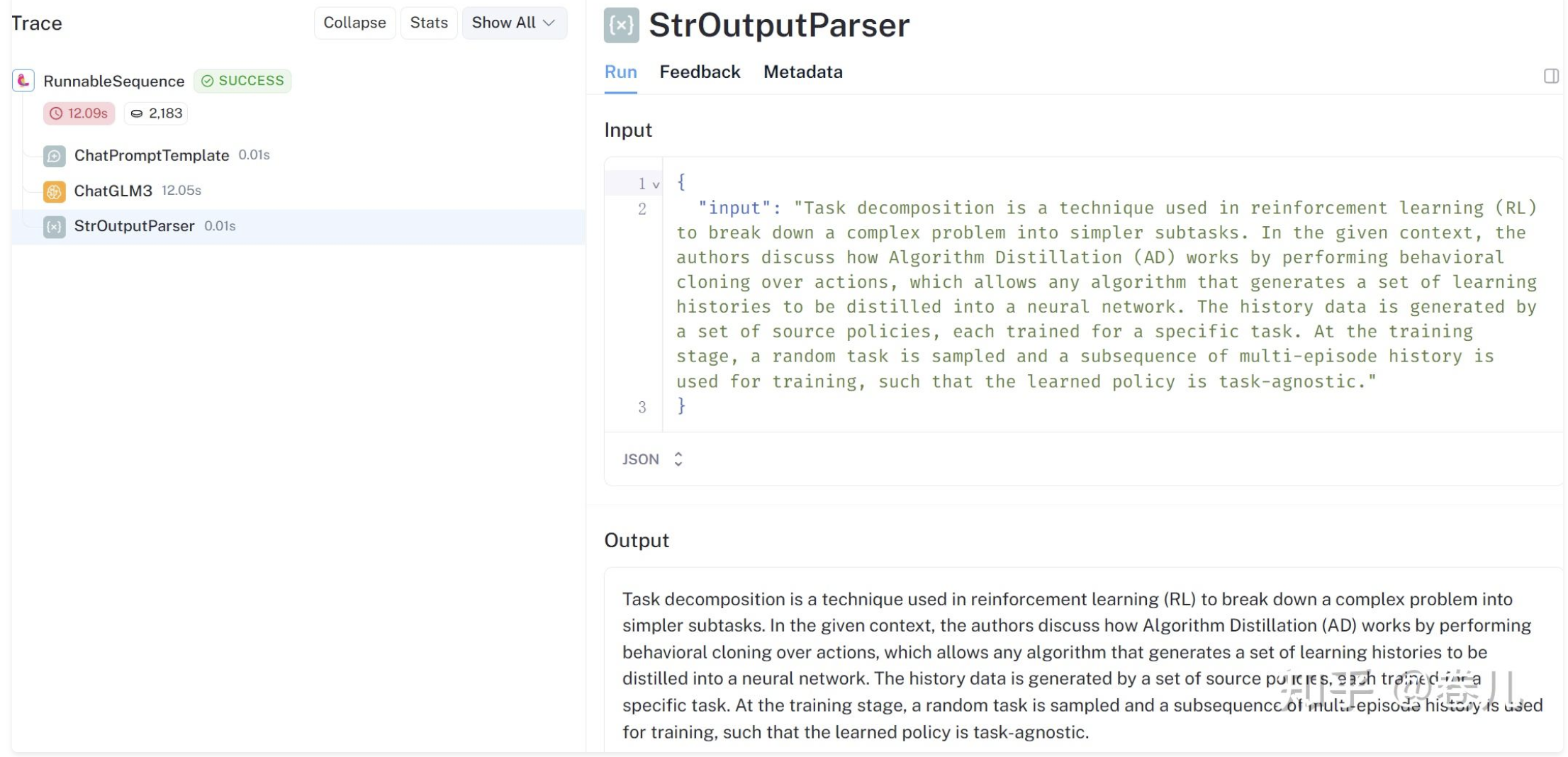
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough, RunnableLambda
from langchain_text_splitters import RecursiveCharacterTextSplitter
from zhipuai import ZhipuAI
from typing import (
AbstractSet,
Any,
Callable,
Collection,
Iterable,
List,
Literal,
Optional,
Sequence,
Type,
TypeVar,
Union,
)
unique_id = uuid4().hex[0:8]
os.environ["LANGCHAIN_PROJECT"] = f" [语境压缩] 内容过滤 qianfan Tracing Walkthrough - {unique_id}"
os.environ["LANGCHAIN_API_KEY"] = os.getenv('MY_LANGCHAIN_API_KEY')
bge_en_v1p5_model_path = "D:\\LLM\\Bge_models\\bge-base-en-v1.5"
embeddings_model = HuggingFaceEmbeddings(
model_name=bge_en_v1p5_model_path,
model_kwargs={'device': 'cuda:0'},
encode_kwargs={'batch_size': 32, 'normalize_embeddings': True, }
)
vectorstore = ElasticsearchStore(
es_url=os.environ['ELASTIC_HOST_HTTP'],
index_name="index_sd_1024_vectors",
embedding=embeddings_model,
es_user="elastic",
vector_query_field='question_vectors',
es_password=os.environ['ELASTIC_ACCESS_PASSWORD']
)
retriever = vectorstore.as_retriever(search_kwargs={"k": 4})
os.environ["AZURE_OPENAI_API_KEY"] = os.getenv('MY_AZURE_OPENAI_API_KEY')
os.environ["AZURE_OPENAI_ENDPOINT"] = os.getenv('MY_AZURE_OPENAI_ENDPOINT')
DEPLOYMENT_NAME_GPT3P5 = os.getenv('MY_DEPLOYMENT_NAME_GPT3P5')
azure_chat = AzureChatOpenAI(
openai_api_version="2023-05-15",
azure_deployment=DEPLOYMENT_NAME_GPT3P5,
temperature=0
)
os.environ["QIANFAN_ACCESS_KEY"] = os.getenv('MY_QIANFAN_ACCESS_KEY')
os.environ["QIANFAN_SECRET_KEY"] = os.getenv('MY_QIANFAN_SECRET_KEY')
qianfan_chat = QianfanChatEndpoint(
model="ERNIE-Bot-4"
)
if __name__ == '__main__':
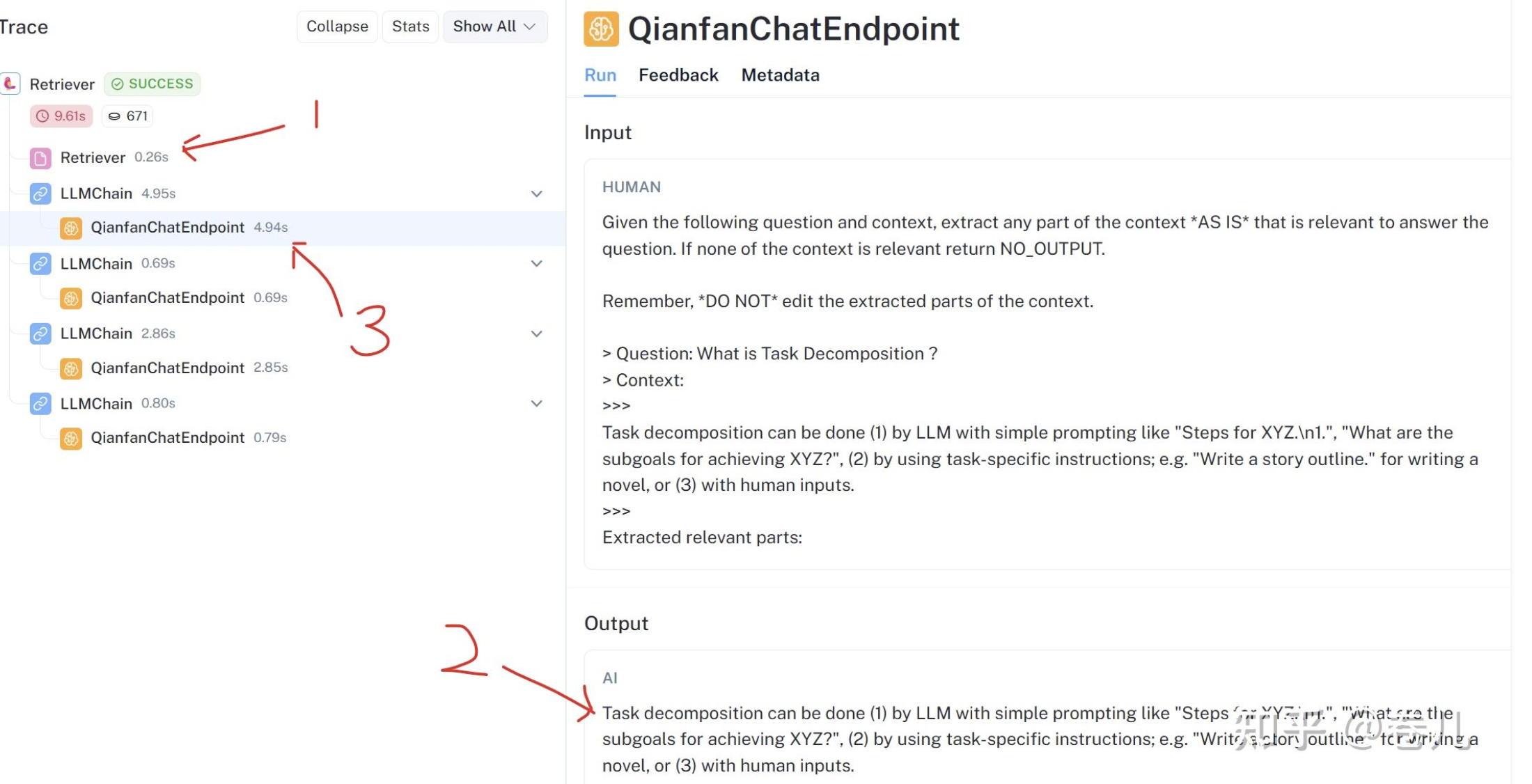
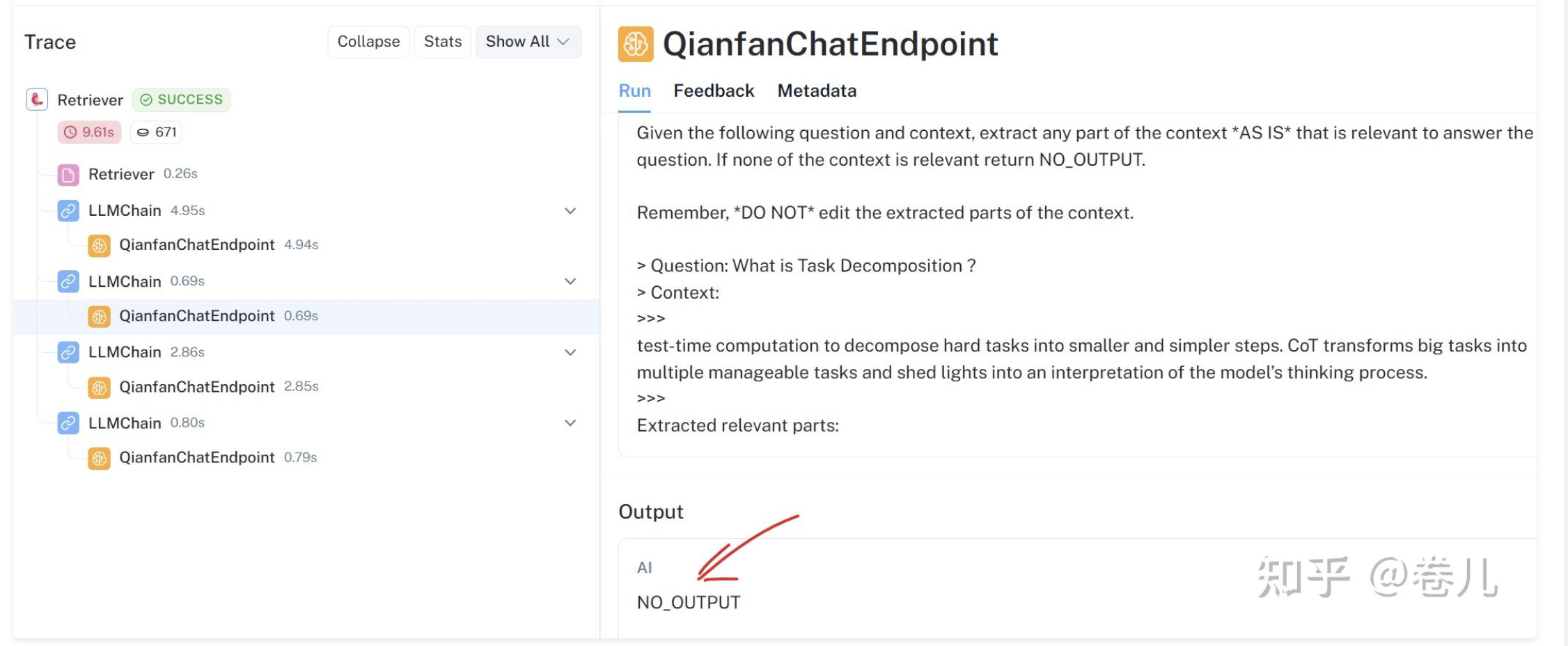
question = "What is Task Decomposition ?"
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=400)
docs = text_splitter.split_documents(docs)
vectorstore.add_documents(docs)
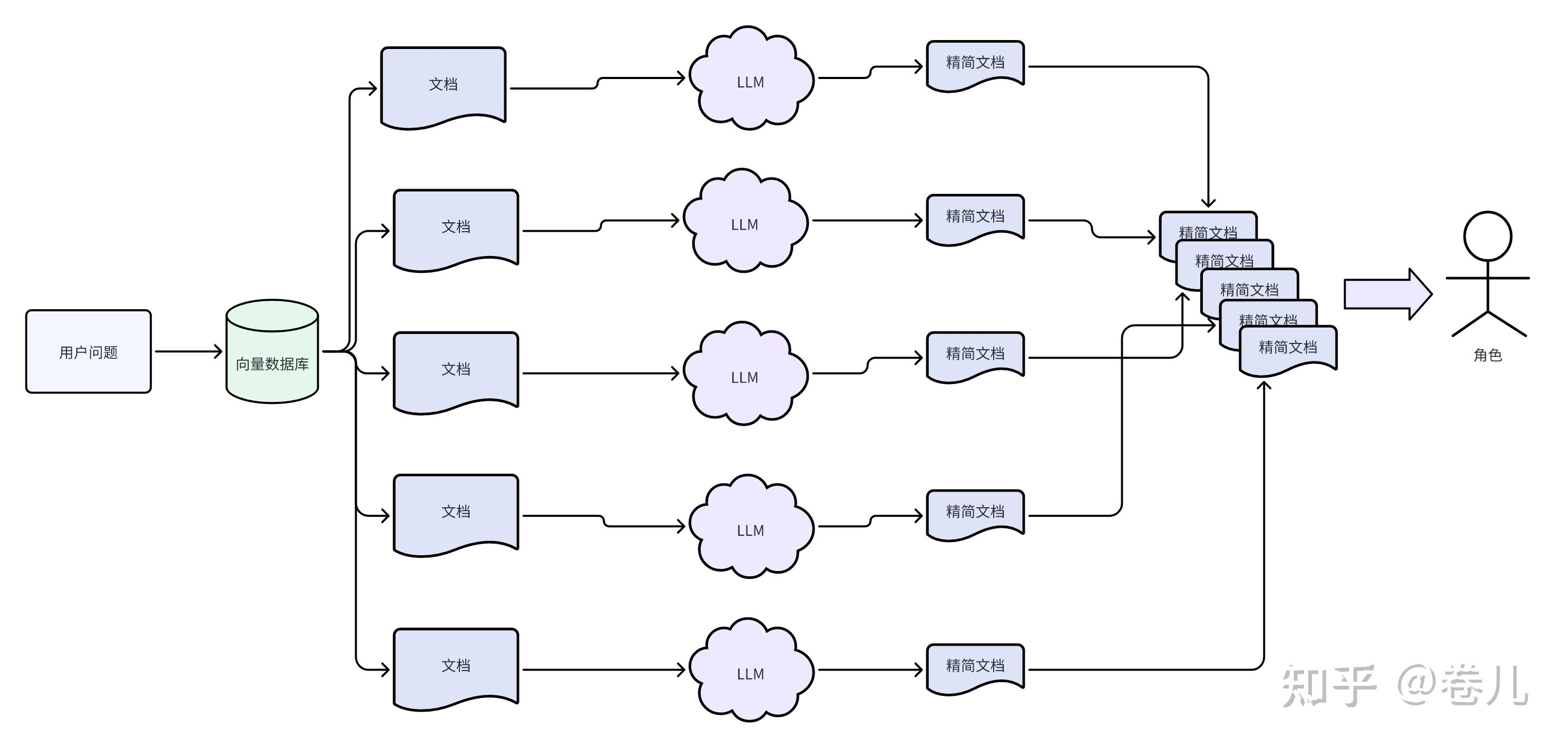
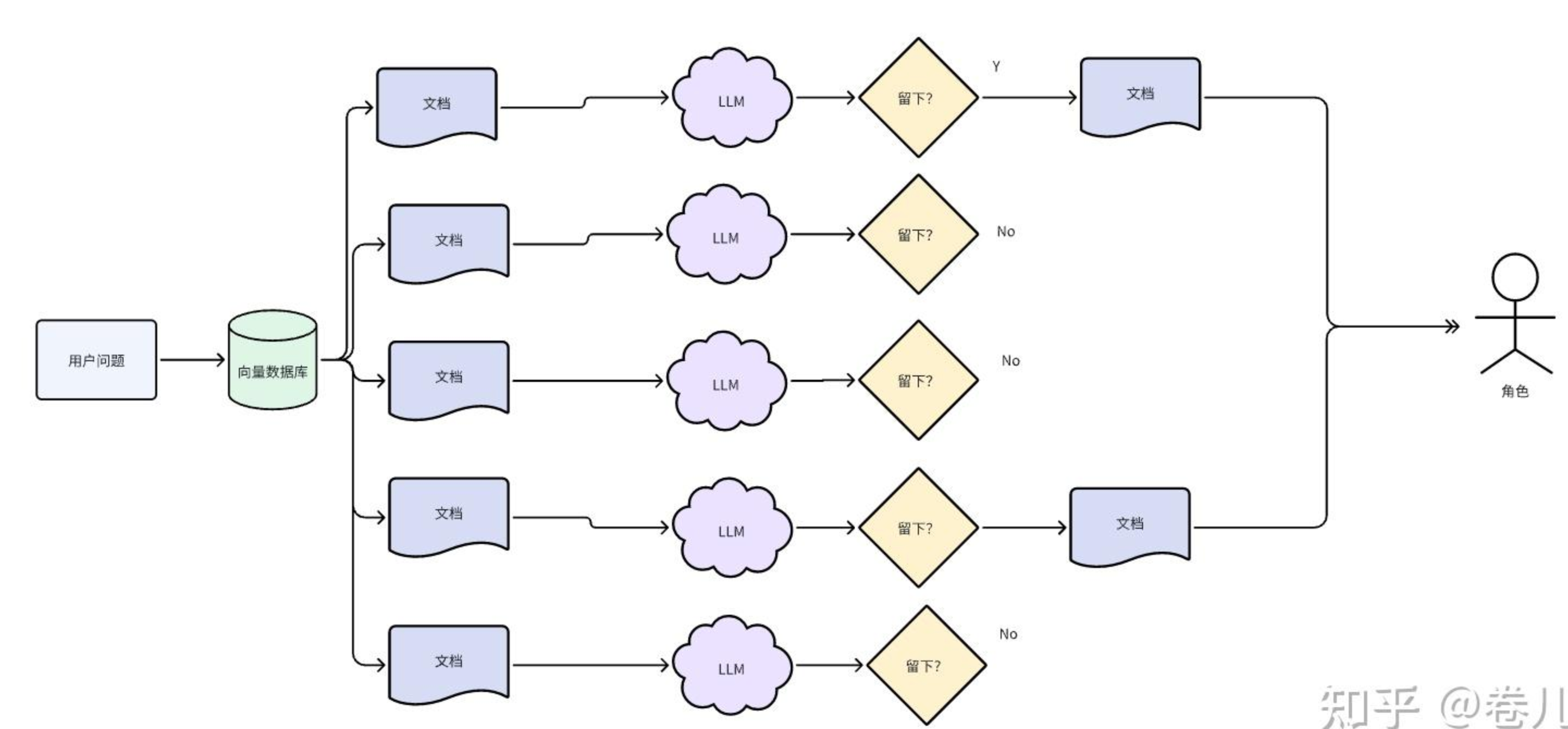
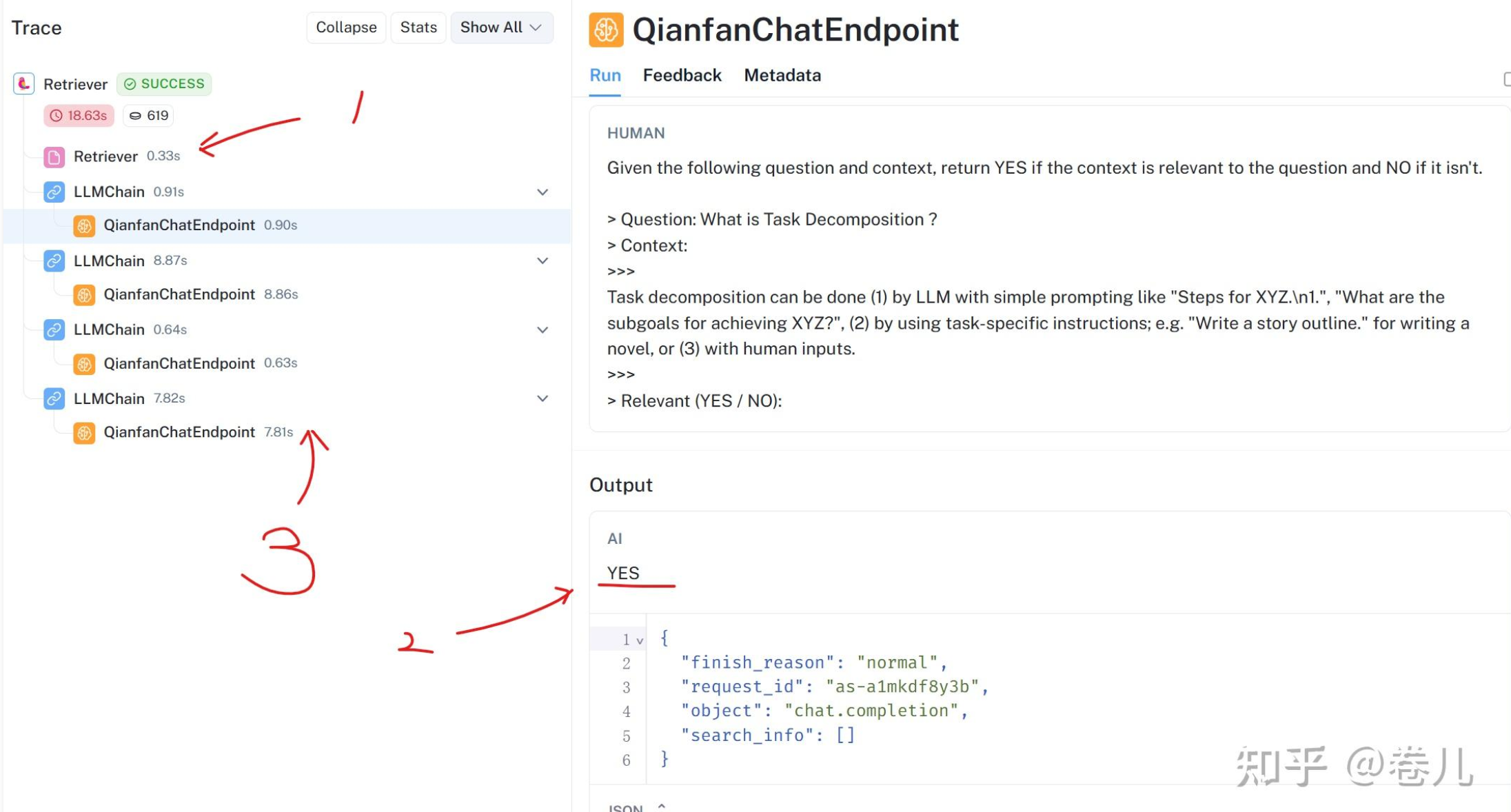
LLMChainFilter
doc_filter = LLMChainFilter.from_llm(qianfan_chat)
filter_retriever = ContextualCompressionRetriever(
base_compressor=doc_filter, base_retriever=retriever
)
filtered_docs = filter_retriever.get_relevant_documents(question)
pass
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=10000)
docs = text_splitter.split_documents(docs)
ZHIPUAI_API_KEY = os.getenv('MY_ZHIPUAI_API_KEY')
client = ZhipuAI(api_key=ZHIPUAI_API_KEY)
question = 'Memory can be defined as what ?'
context = docs[0].page_content
user_msg =f"""
根据给出的问题和上下文,如果上下文与问题相关,则返回YES,如果不相关,则返回NO。
> 问题: {question}
> 上下文:
>>>
{context}
>>>
> 相关(YES / NO):
"""
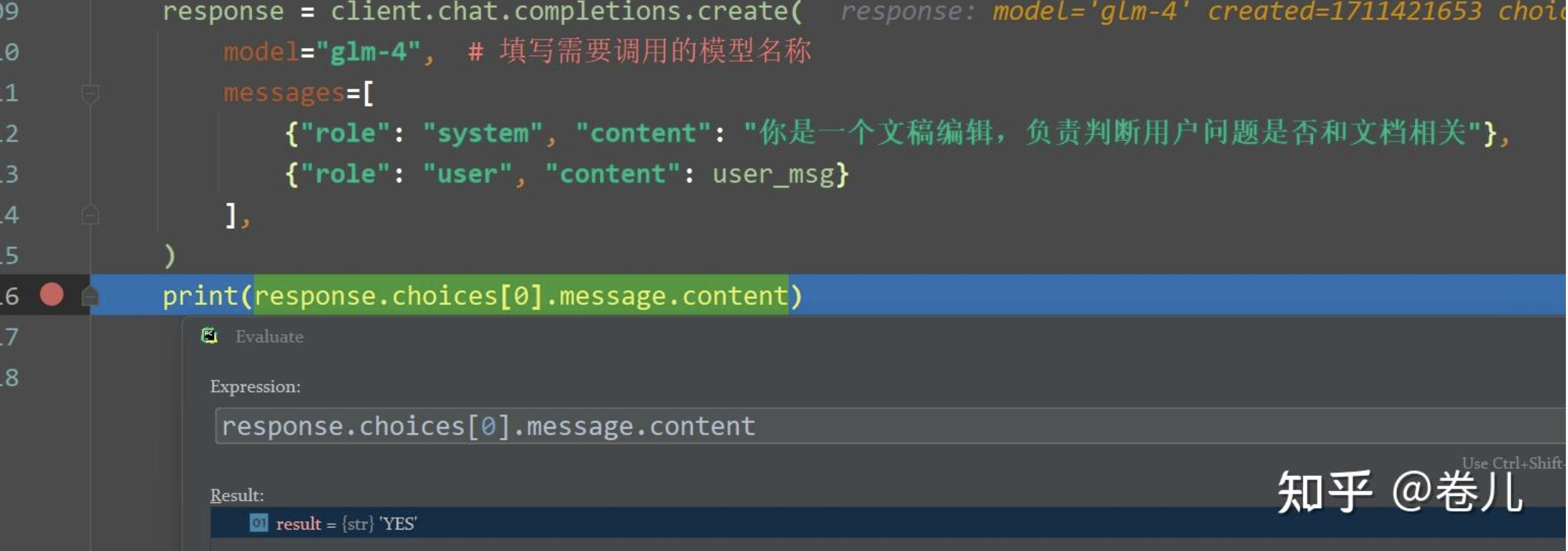
response = client.chat.completions.create(
model="glm-4",
messages=[
{"role": "system", "content": "你是一个文稿编辑,负责判断用户问题是否和文档相关"},
{"role": "user", "content": user_msg}
],
)
print(response.choices[0].message.content)
def local_filter(documents: Iterable[Document]) -> List[Document]:
ZHIPUAI_API_KEY = os.getenv('MY_ZHIPUAI_API_KEY')
client = ZhipuAI(api_key=ZHIPUAI_API_KEY)
new_docs = []
for doc in documents:
context = doc.page_content
user_msg = f"""
根据给出的问题和上下文,如果上下文与问题相关,则返回YES,如果不相关,则返回NO。
> 问题: {question}
> 上下文:
>>>
{context}
>>>
> 相关(DOC_YES / DOC_NO):
"""
response = client.chat.completions.create(
model="glm-4",
messages=[
{"role": "system", "content": "你是一个文稿编辑,负责判断用户问题是否和文档相关"},
{"role": "user", "content": user_msg}
],
)
if 'DOC_YES' in response.choices[0].message.content:
new_docs.append(doc)
return new_docs
template = """Answer the question based only on the following context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
chain = (
{"context": retriever | RunnableLambda(local_filter), "question": RunnablePassthrough()}
| prompt
| qianfan_chat
| StrOutputParser()
)
res = chain.invoke(question)
pass
|