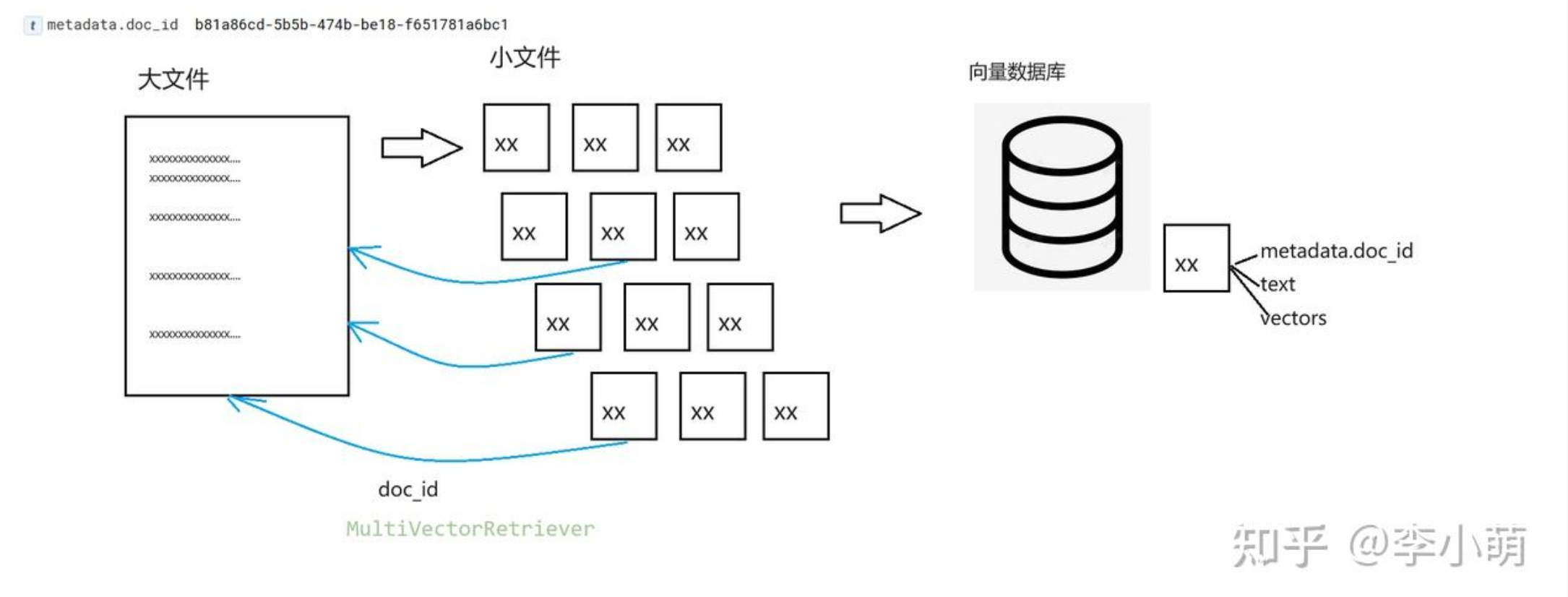
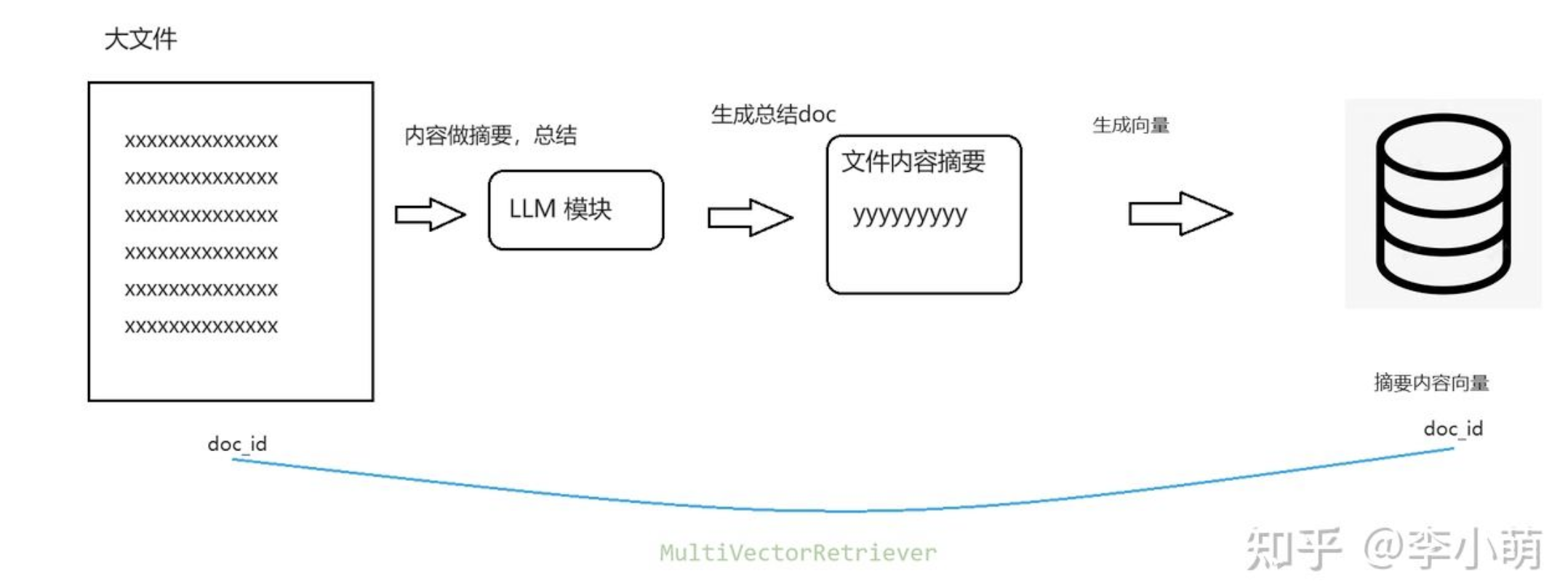
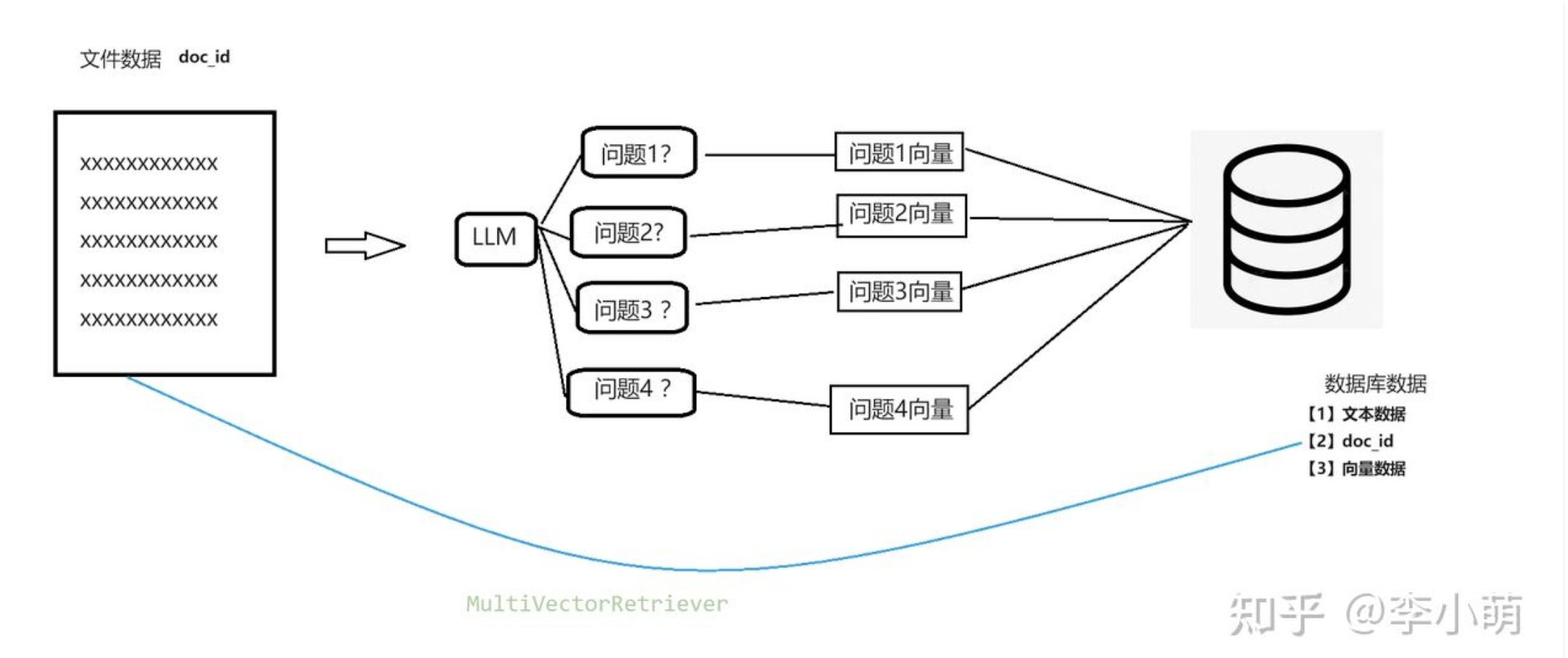
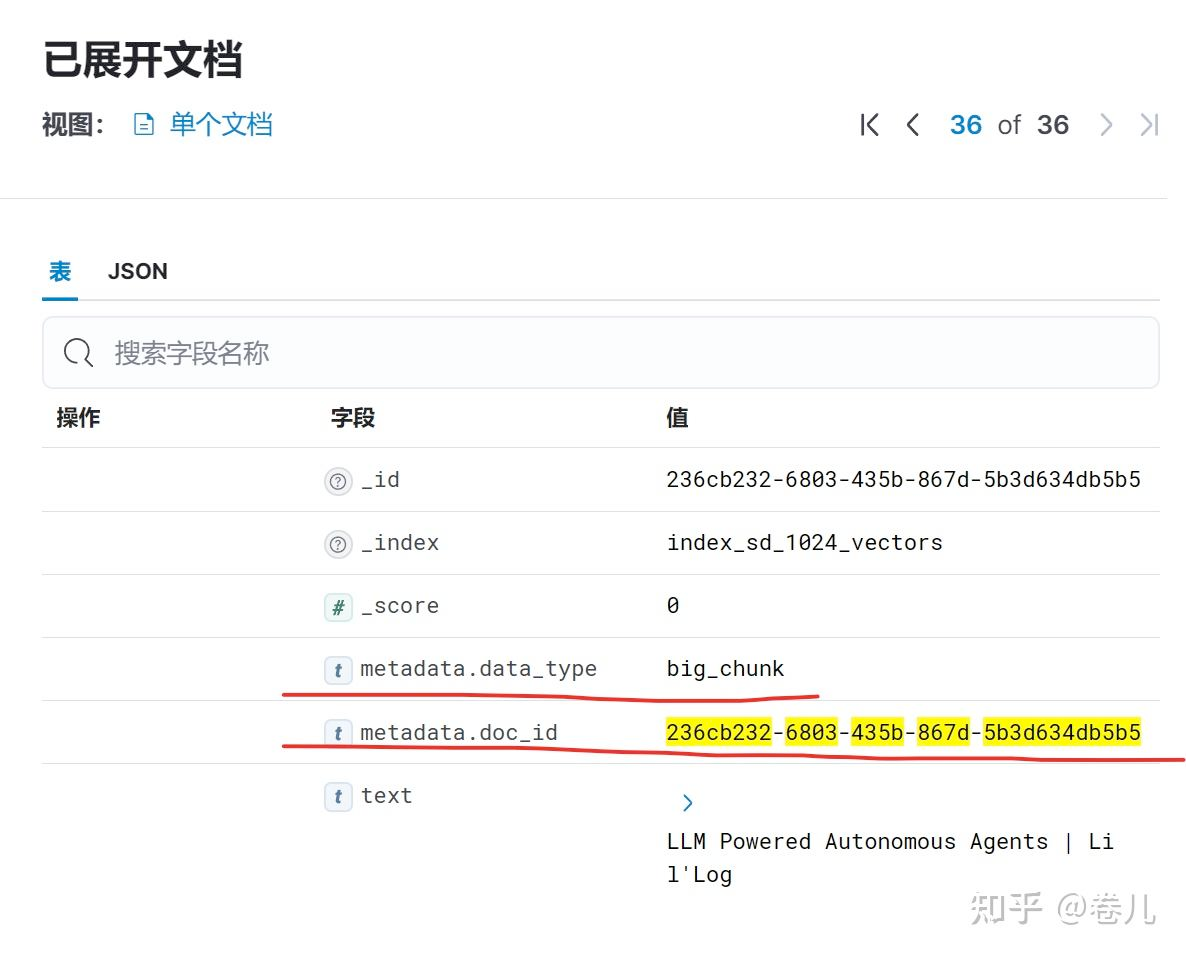
# The storage layer for the parent documents store = InMemoryByteStore() id_key = "doc_id" # The retriever (empty to start) retriever = MultiVectorRetriever( vectorstore=vectorstore, byte_store=store, id_key=id_key, )
doc_ids = [str(uuid.uuid4()) for _ in docs]
# The splitter to use to create smaller chunks child_text_splitter = RecursiveCharacterTextSplitter(chunk_size=400)
sub_docs = [] for i, doc inenumerate(docs): _id = doc_ids[i] _sub_docs = child_text_splitter.split_documents([doc]) for _doc in _sub_docs: _doc.metadata[id_key] = _id sub_docs.extend(_sub_docs)
question = "What are the approaches to Task Decomposition?"
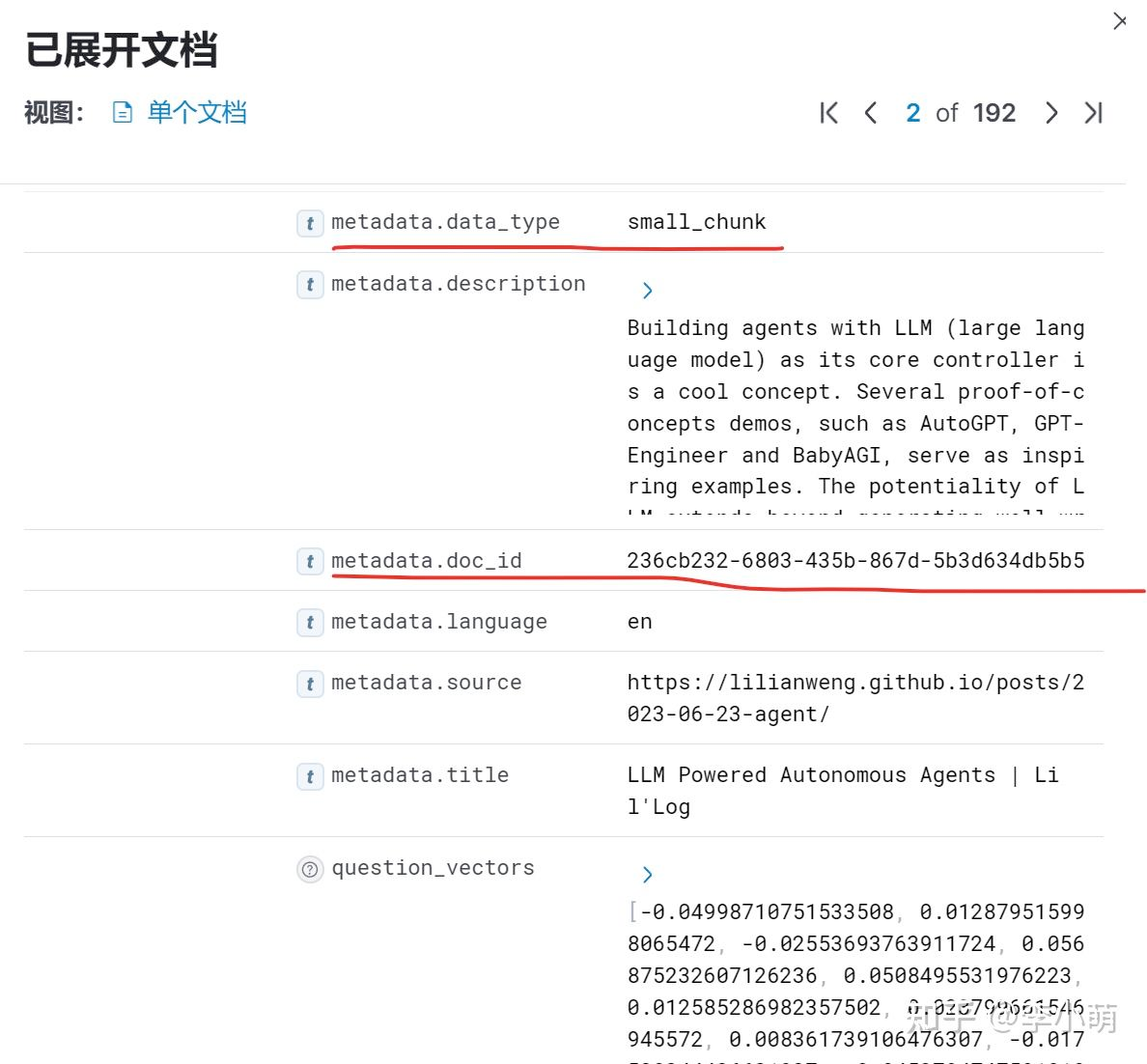
for i, doc inenumerate(docs): _id = doc_ids[i] _sub_docs = child_text_splitter.split_documents([doc]) for _doc in _sub_docs: _doc.metadata[id_key] = _id _doc.metadata['data_type'] = 'small_chunk'
from langchain import hub from langchain.agents import create_openai_tools_agent, AgentExecutor from langchain.retrievers import EnsembleRetriever, MultiQueryRetriever, MultiVectorRetriever from langchain.storage import InMemoryByteStore from langchain.tools.retriever import create_retriever_tool from langchain_community.chat_models.azure_openai import AzureChatOpenAI from langchain_community.document_loaders.web_base import WebBaseLoader
from langchain_community.embeddings import HuggingFaceEmbeddings, QianfanEmbeddingsEndpoint from langchain_community.retrievers import ElasticSearchBM25Retriever from langchain_community.vectorstores.chroma import Chroma from langchain_community.vectorstores.elasticsearch import ElasticsearchStore from langchain_core.documents import Document from langchain_text_splitters import RecursiveCharacterTextSplitter import uuid
for i, doc inenumerate(docs): _id = doc_ids[i] _sub_docs = child_text_splitter.split_documents([doc]) for _doc in _sub_docs: _doc.metadata[id_key] = _id _doc.metadata['data_type'] = 'small_chunk'