from langchain_core.pydantic_v1 import BaseModel, Field
classPerson(BaseModel): """Information about a person."""
# ^ Doc-string for the entity Person. # This doc-string is sent to the LLM as the description of the schema Person, # and it can help to improve extraction results.
# Note that: # 1. Each field is an `optional` -- this allows the model to decline to extract it! # 2. Each field has a `description` -- this description is used by the LLM. # Having a good description can help improve extraction results. name: Optional[str] = Field(..., description="The name of the person") hair_color: Optional[str] = Field( ..., description="The color of the peron's hair if known" ) height_in_meters: Optional[str] = Field( ..., description="Height measured in meters" )
from langchain_core.pydantic_v1 import BaseModel, Field
classPerson(BaseModel): """Information about a person."""
# ^ Doc-string for the entity Person. # This doc-string is sent to the LLM as the description of the schema Person, # and it can help to improve extraction results.
# Note that: # 1. Each field is an `optional` -- this allows the model to decline to extract it! # 2. Each field has a `description` -- this description is used by the LLM. # Having a good description can help improve extraction results. name: Optional[str] = Field(..., description="The name of the person") hair_color: Optional[str] = Field( ..., description="The color of the peron's hair if known" ) height_in_meters: Optional[str] = Field( ..., description="Height measured in meters" )
classData(BaseModel): """Extracted data about people."""
# Creates a model so that we can extract multiple entities. people: List[Person]
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder from typing importList, Optional
from langchain_core.pydantic_v1 import BaseModel, Field from langchain_openai import ChatOpenAI, AzureChatOpenAI import uuid from typing importDict, List, TypedDict
from langchain_core.messages import ( AIMessage, BaseMessage, HumanMessage, SystemMessage, ToolMessage, ) from langchain_core.pydantic_v1 import BaseModel, Field
classExample(TypedDict): """A representation of an example consisting of text input and expected tool calls. For extraction, the tool calls are represented as instances of pydantic model. """
input: str# This is the example text tool_calls: List[BaseModel] # Instances of pydantic model that should be extracted
deftool_example_to_messages(example: Example) -> List[BaseMessage]: messages: List[BaseMessage] = [HumanMessage(content=example["input"])] openai_tool_calls = [] for tool_call in example["tool_calls"]: openai_tool_calls.append( { "id": str(uuid.uuid4()), "type": "function", "function": { "name": tool_call.__class__.__name__, "arguments": tool_call.json(), }, } ) messages.append( AIMessage(content="", additional_kwargs={"tool_calls": openai_tool_calls}) ) tool_outputs = example.get("tool_outputs") or [ "You have correctly called this tool." ] * len(openai_tool_calls) for output, tool_call inzip(tool_outputs, openai_tool_calls): messages.append(ToolMessage(content=output, tool_call_id=tool_call["id"])) return messages
from langchain.chains.llm import LLMChain from langchain_community.chat_models.baidu_qianfan_endpoint import QianfanChatEndpoint from langchain_core.output_parsers import StrOutputParser from langchain_core.prompts import PromptTemplate, ChatPromptTemplate
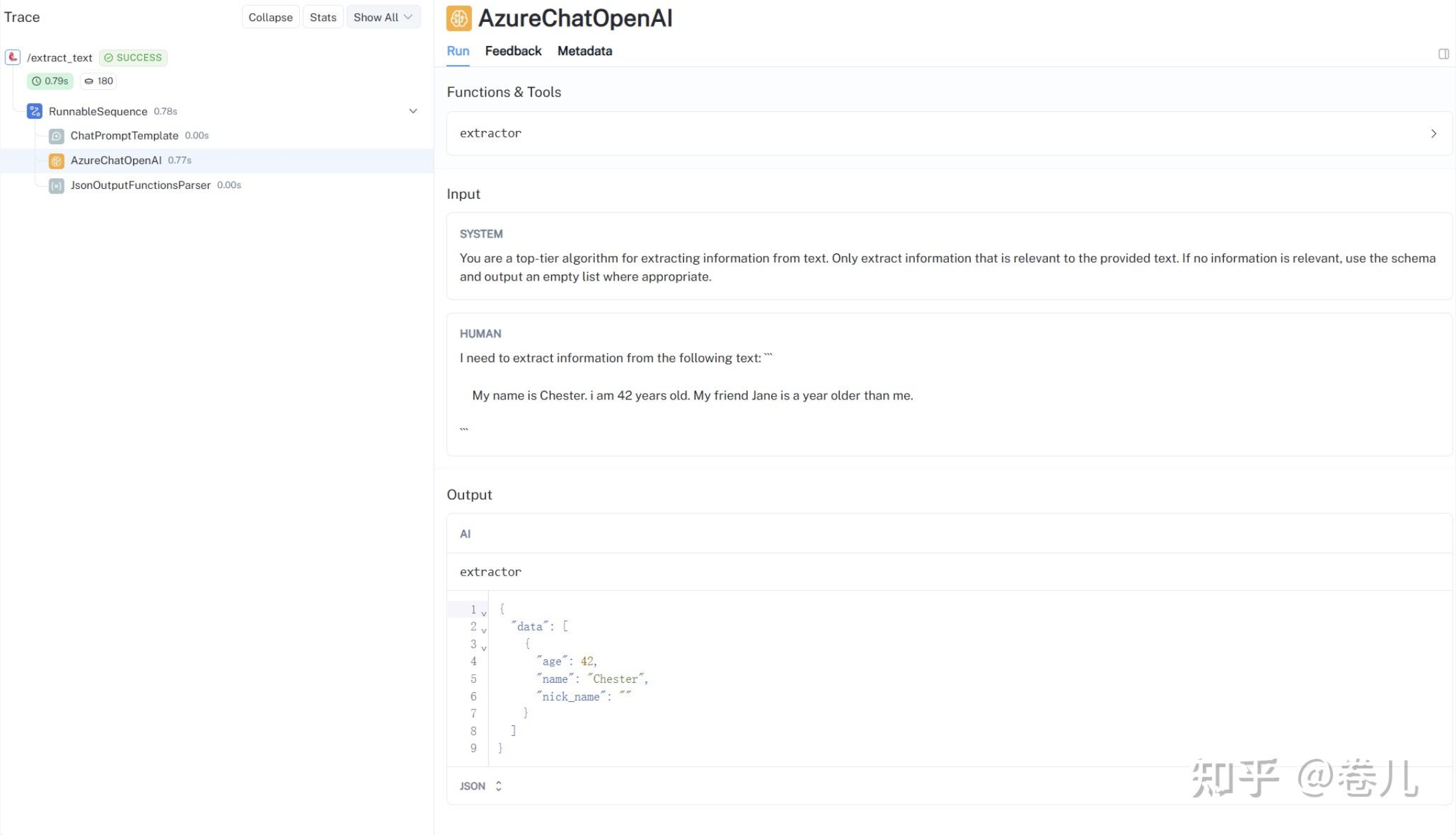
#Schema classPerson(BaseModel): age: Optional[int] = Field(None, description="The age of the person in years.") name: Optional[str] = Field(None, description="The name of the person.") nick_name: Optional[str] = Field(None, description="Alias, if any.")