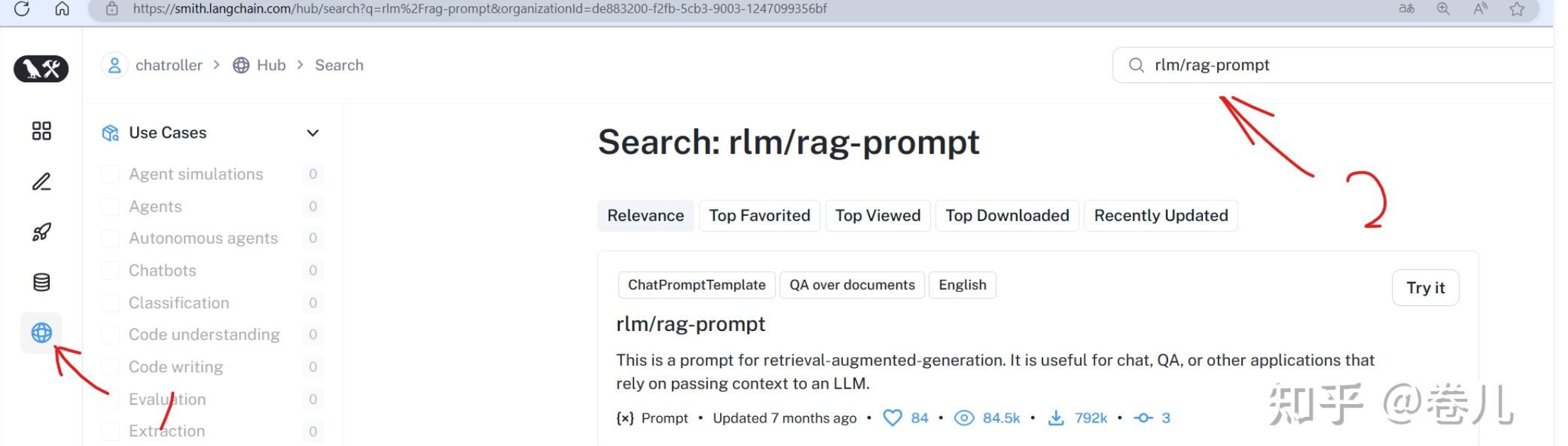
template = """Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer. Use three sentences maximum and keep the answer as concise as possible. Always say "thanks for asking!" at the end of the answer. {context} Question: {question} Helpful Answer:""" custom_rag_prompt = PromptTemplate.from_template(template)
import os from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain_community.chat_models import QianfanChatEndpoint from langchain_community.document_loaders import TextLoader, DirectoryLoader from langchain_community.embeddings import QianfanEmbeddingsEndpoint from langchain import hub from langchain_community.vectorstores.elasticsearch import ElasticsearchStore from langchain_core.output_parsers import StrOutputParser from langchain_core.prompts import PromptTemplate from langchain_core.runnables import RunnablePassthrough
# 【1-2】 分割数据 text_splitter = RecursiveCharacterTextSplitter( # Set a really small chunk size, just to show. chunk_size=400, chunk_overlap=0, length_function=len, )
# 分割Document 对象 doc_list = [] for doc in docs: tmp_docs = text_splitter.create_documents([doc.page_content]) doc_list += tmp_docs
template = """Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer. Use three sentences maximum and keep the answer as concise as possible. Always say "thanks for asking!" at the end of the answer. {context} Question: {question} Helpful Answer:""" custom_rag_prompt = PromptTemplate.from_template(template)
from fastapi import FastAPI from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain_community.chat_models import QianfanChatEndpoint from langchain_community.document_loaders import TextLoader, DirectoryLoader from langchain_community.embeddings import QianfanEmbeddingsEndpoint from langchain import hub from langchain_community.vectorstores.elasticsearch import ElasticsearchStore from langchain_core.output_parsers import StrOutputParser from langchain_core.prompts import PromptTemplate from langchain_core.runnables import RunnablePassthrough from langserve import add_routes
template = """Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer. Use three sentences maximum and keep the answer as concise as possible. Always say "thanks for asking!" at the end of the answer. {context} Question: {question} Helpful Answer:""" custom_rag_prompt = PromptTemplate.from_template(template)
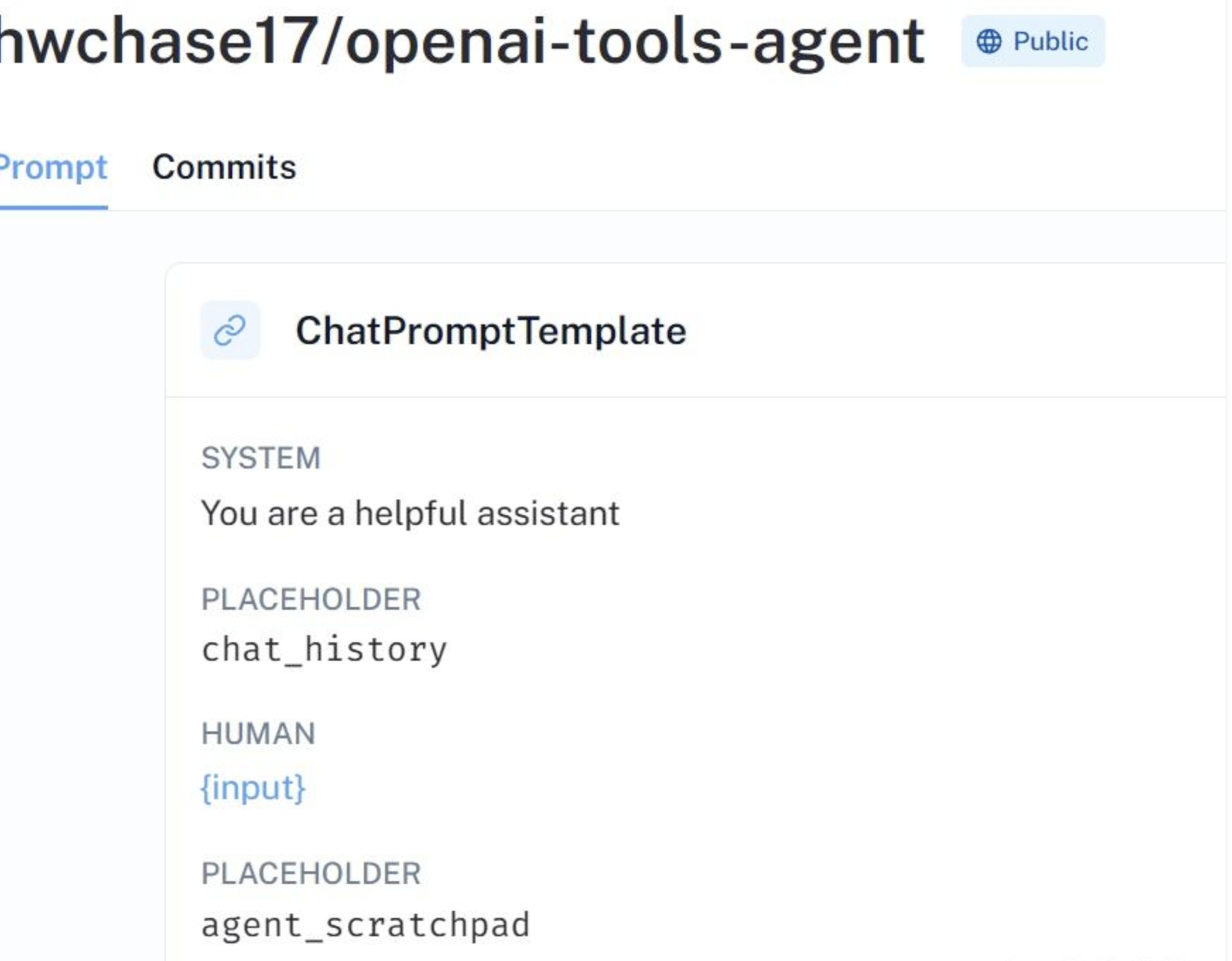
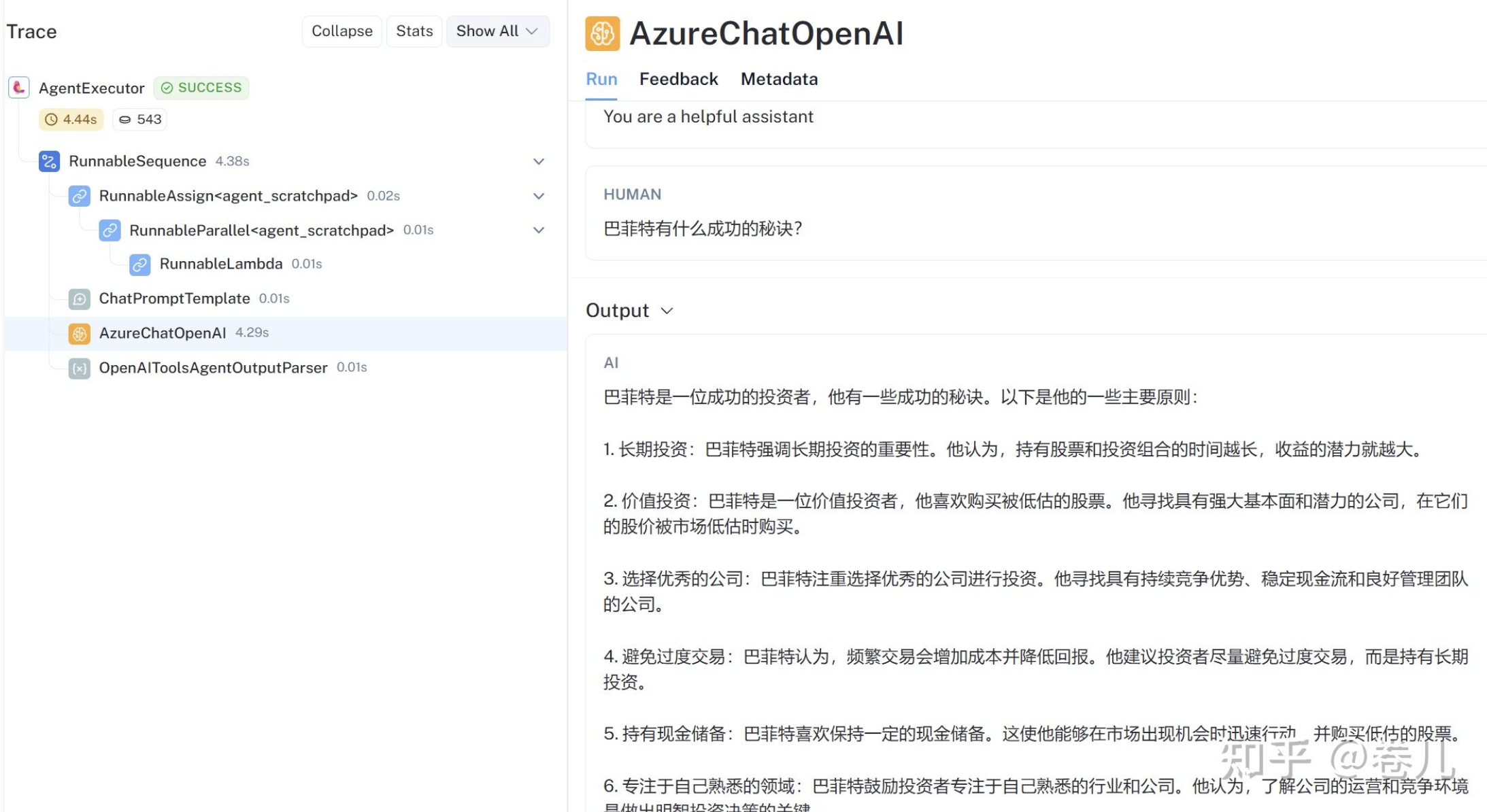
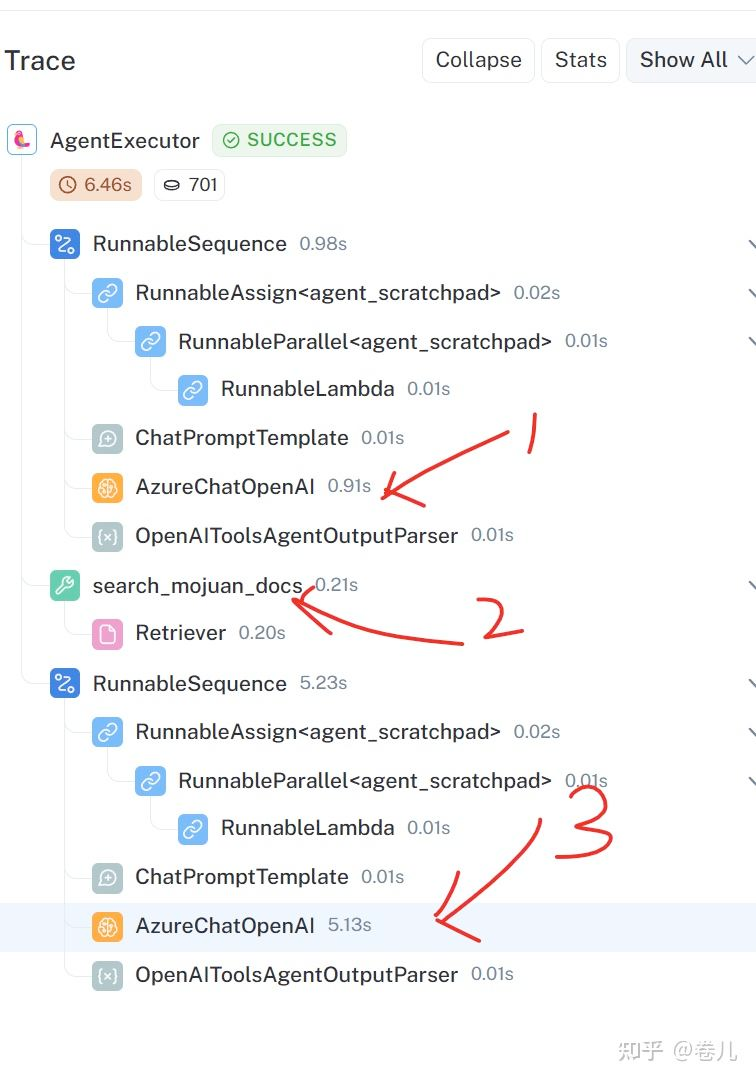
from langchain.agents import create_openai_tools_agent, AgentExecutor from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain.tools.retriever import create_retriever_tool from langchain_community.chat_models import QianfanChatEndpoint from langchain_community.chat_models.azure_openai import AzureChatOpenAI from langchain_community.document_loaders import TextLoader, DirectoryLoader from langchain_community.embeddings import QianfanEmbeddingsEndpoint from langchain import hub from langchain_community.vectorstores.elasticsearch import ElasticsearchStore from langchain_core.output_parsers import StrOutputParser from langchain_core.prompts import PromptTemplate from langchain_core.runnables import RunnablePassthrough