注意本文只是一个思路,实际上常规业务场景并不会采用这个方案。 基于用户的搜索
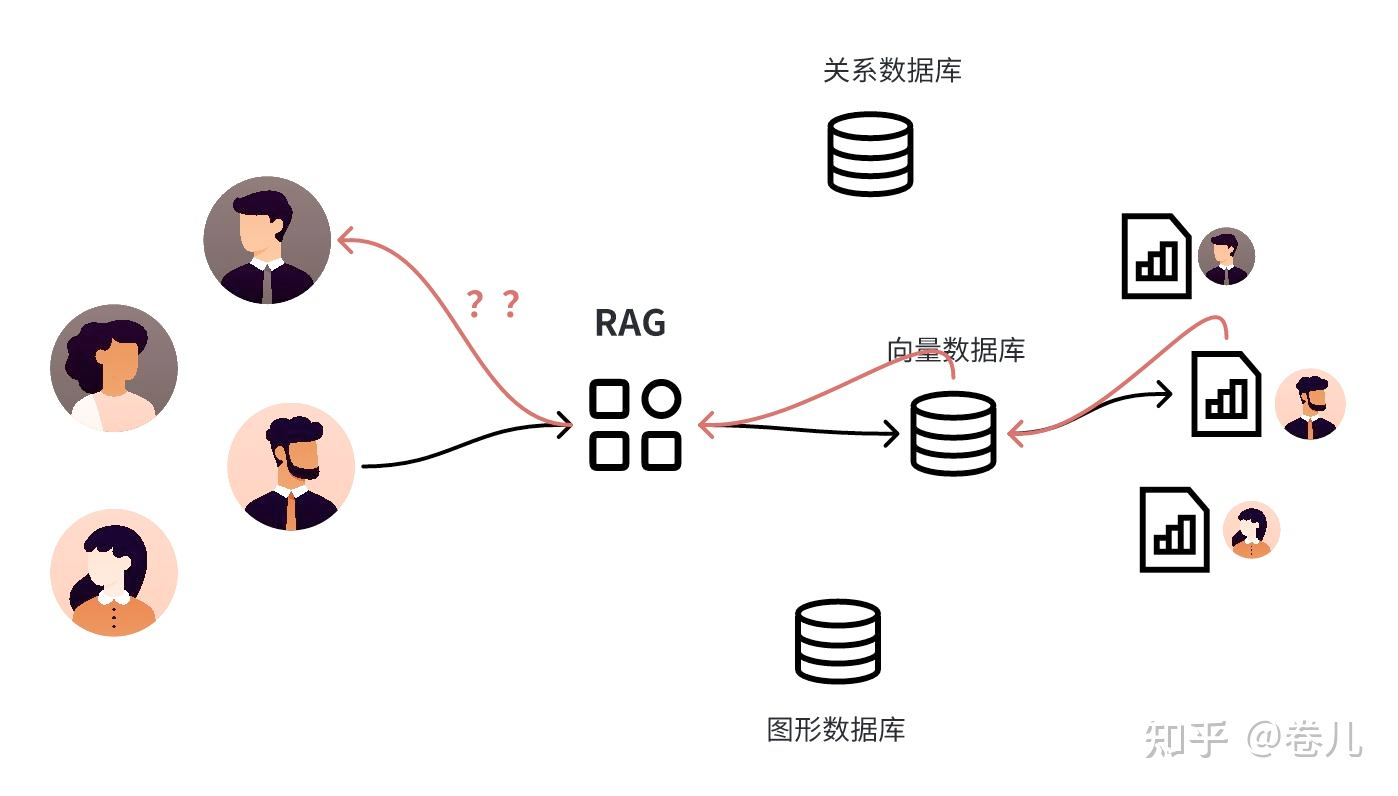
当构建一个检索应用时,你通常需要考虑 到多个用户 。
目前,LangChain 中没有统一的标志或过滤器来实现这一点。相反,每个向量存储和检索器可能都有自己的实现,并且可能被称为不同的事物。 对于向量存储来说,这通常作为一个关键字参数在 similarity_search 过程中传递。通过阅读文档或源代码,弄清楚你使用的检索器是否支持多个用户,如果支持,如何使用它。这意味着你可能不仅仅是为一个用户存储数据,而是为许多不同的用户存储数据,他们不应该能够看到彼此的数据 。
实现步骤:
第一步:确保你使用的检索器支持多个用户 (自己设计数据存储结构)
第二步:将该参数作为一个可配置字段添加到链中(当作参数传递)
第三步:使用该可配置字段调用链(调用时,区分用户)
1 2 3 4 比如ElasticSearch 在相似度搜索时,可以添加过滤参数 docs = vectorstore.similarity_search( query_text, filter =[{"term" : {"metadata.author.keyword" : "userid_002" }}] )
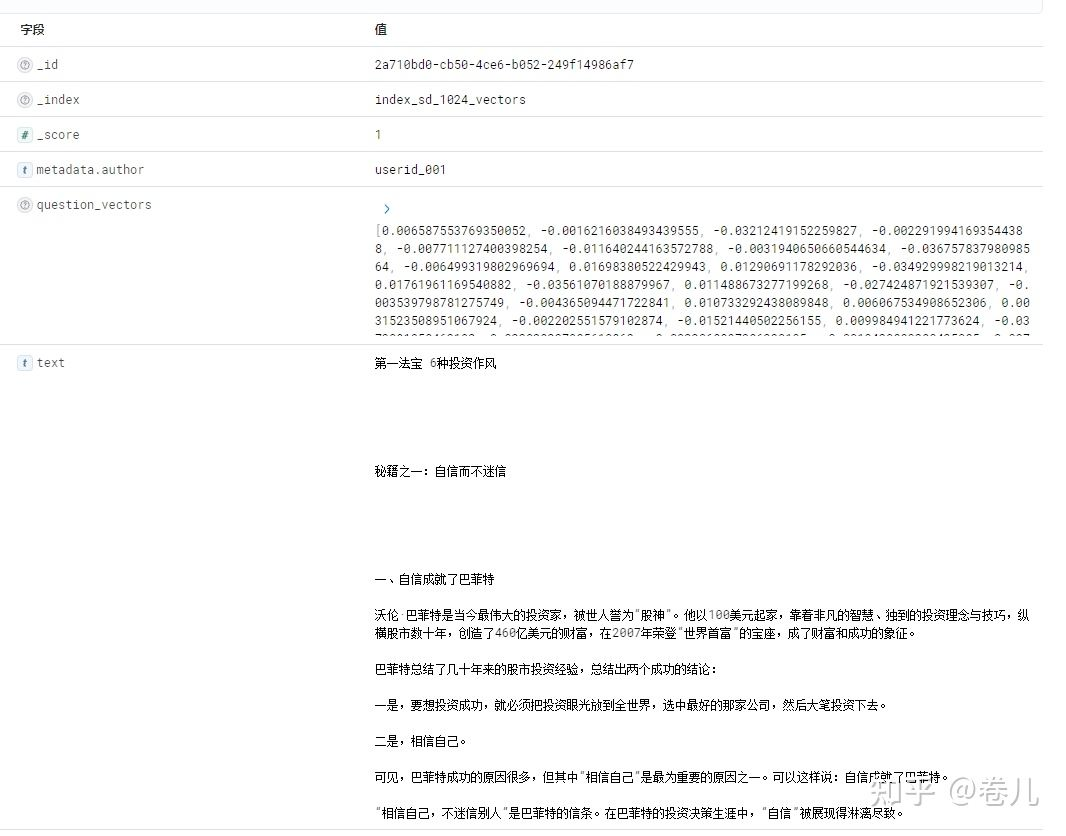
巴菲特与索罗斯21个投资秘籍.txt 是docs[0],作者 userid_001
维特根斯坦读本.txt 是docs[1],作者 userid_022
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 doc_list = [] owner_one_doc = docs[0 ] owner_one_docs = text_splitter.create_documents([owner_one_doc.page_content]) for i, doc in enumerate (owner_one_docs): doc.metadata["author" ] = ["userid_001" ] doc_list.append(doc) owner_two_doc = docs[1 ] owner_two_docs = text_splitter.create_documents([owner_two_doc.page_content]) for i, doc in enumerate (owner_two_docs): doc.metadata["author" ] = ["userid_022" ] doc_list.append(doc)
生成过滤特定用户的检索器
1 2 3 4 5 6 7 8 9 user_id= "userid_001" filter_criteria = [{"term" : {"metadata.author.keyword" : user_id}}] special_retriever = vectorstore.as_retriever(search_kwargs={'filter' : filter_criteria})
测试你的效果
1 2 3 4 5 test_chain = RunnableParallel( {"context" : special_retriever, "question" : RunnablePassthrough()} ) test_docs = test_chain.invoke("谁在2007年荣登“世界首富”的宝座,成了财富和成功的象征?" )
建立问答chain
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 template = """使用下面的资料中的内容回答问题,如果没有资料,就回答:资料不全,无法回答您的问题。 参考资料: {context} 用户问题: {question} 你的回答:""" custom_rag_prompt = PromptTemplate.from_template(template) chat = QianfanChatEndpoint(model="ERNIE-Bot-4" ) def format_docs (docs ): return "\n\n" .join(doc.page_content for doc in docs) user_id= "userid_001" filter_criteria = [{"term" : {"metadata.author.keyword" : user_id}}] special_retriever = vectorstore.as_retriever(search_kwargs={'filter' : filter_criteria}) rag_chain = ( {"context" : special_retriever | format_docs, "question" : RunnablePassthrough()} | custom_rag_prompt | chat | StrOutputParser() )
在userid_001 的文档中,有下面一段话
但巴菲特 却从来不被技术分析师的预测所左右,他从不相信所谓的“权威分析”。不仅如此,就连他的老师格雷厄姆的投资理论他都不迷信。
我的问题:谁从来不被技术分析师的预测所左右?
上面的问题是有语境的,只有context里有这句话,才能正确回答。
当我用user_id= “userid_001” 时
1 巴菲特从来不被技术分析师的预测所左右。他通常不会花时间去阅读证券公司的报告或听取技术分析师的预测,因为他认为这些预测是非常漂浮不定的,不值得他这个长远的价值投资者一用。相反,他更注重自己的独立分析和价值投资原则,从而取得了长期的投资成功。
*当我用user_id= “*userid_002* “ 时 *
1 很抱歉,我无法准确回答这个问题,因为这个问题可能有很多可能的答案,且需要更多的上下文信息来确定。
在回答中添加引文信息
【1】用户问题
【2】服务端查询的文档
【3】服务端回答
【4】引文信息
关键提示词
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 system = """You're a helpful AI assistant. Given a user question and some document snippets, \ answer the user question and provide citations. If none of the articles answer the question, just say you don't know. Remember, you must return both an answer and citations. A citation consists of a VERBATIM quote that \ justifies the answer and the ID of the quote article. Return a citation for every quote across all articles \ that justify the answer. Use the following format for your final output: <cited_answer> <answer></answer> <citations> <citation><source_id></source_id><quote></quote></citation> <citation><source_id></source_id><quote></quote></citation> ... </citations> </cited_answer> Here are the document:{context}""" prompt = ChatPromptTemplate.from_messages( [("system" , system), ("human" , "{question}" )] )
source_id 来自哪里? 召回文档后,自己拼接产生你需要的“引文”格式
1 2 3 4 5 6 7 8 9 10 def format_docs (docs: List [Document] ) -> str : formatted = [] for i, doc in enumerate (docs): doc_str = f"""\ <source id=\"{i} \"> <article_snippet>{doc.page_content} </article_snippet> </source>""" formatted.append(doc_str) final_text = "\n\n<sources>" + "\n" .join(formatted) + "</sources>" return final_text
拼接后
1 2 3 4 <source id ="0" > <article_snippet>因此,常常会有一些证券公司... </article_snippet> </source>
问答chain
1 2 3 4 5 6 7 8 9 10 11 12 format = itemgetter("docs" ) | RunnableLambda(format_docs)answer = prompt | chat | StrOutputParser() chain = ( RunnableParallel(question=RunnablePassthrough(), docs=retriever) .assign(context=format ) .assign(cited_answer=answer) .pick(["cited_answer" , "docs" ]) ) res = chain.invoke("谁从来不被技术分析师的预测所左右?" ) ai_res = res['cited_answer' ]
输出
1 2 3 4 5 6 7 8 9 10 11 {'cited_answer' : '<cited_answer>\n <answer>巴菲特从来不被技术分析师的预测所左右。</answer>\n <citations>\n <citation> <source_id>0</source_id> <quote>巴菲特却从来不被技术分析师的预测所左右,他从不相信所谓的“权威分析”。 </quote> </citation>\n </citations>\n </cited_answer>' , ...
解析上面的内容
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 def parse_response_to_json (text ): pre_answer_match = re.search(r'^(.*?)(?=<cited_answer>)' , text, re.DOTALL) pre_answer_text = pre_answer_match.group(1 ).strip() if pre_answer_match else None cited_answer_match = re.search(r'<cited_answer>(.*?)<\/cited_answer>' , text, re.DOTALL) cited_answer_text = cited_answer_match.group(1 ).strip() if cited_answer_match else None output_json = { "response" : pre_answer_text, "cited_answer" : None } if cited_answer_text: answer_match = re.search(r'<answer>(.*?)<\/answer>' , cited_answer_text) citations_match = re.findall( r'<citation>\s*<source_id>(.*?)<\/source_id>\s*<quote>(.*?)<\/quote>\s*<\/citation>' , cited_answer_text, re.DOTALL) cited_answer_part = { "answer" : answer_match.group(1 ).strip() if answer_match else None , "citations" : [] } for source_id, quote in citations_match: cited_answer_part["citations" ].append({ "source_id" : source_id.strip(), "quote" : quote.strip() }) output_json["cited_answer" ] = cited_answer_part return json.dumps(output_json, ensure_ascii=False , indent=4 )
解析后
1 2 3 4 5 6 ai_res = res['cited_answer' ] json_obj_str = parse_response_to_json(ai_res) print (res) json_obj_obj = json.loads(json_obj_str) print (json_obj_obj) {'response' : '' , 'cited_answer' : {'answer' : '巴菲特从来不被技术分析师的预测所左右。' , 'citations' : [{'source_id' : '0' , 'quote' : '巴菲特却从来不被技术分析师的预测所左右,他从不相信所谓的“权威分析”。' }]}}
代码
基于用户的搜索
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 import osfrom langchain.text_splitter import RecursiveCharacterTextSplitterfrom langchain_community.chat_models import QianfanChatEndpointfrom langchain_community.document_loaders import TextLoader, DirectoryLoaderfrom langchain_community.embeddings import QianfanEmbeddingsEndpoint, HuggingFaceEmbeddingsfrom langchain_community.vectorstores.elasticsearch import ElasticsearchStorefrom langchain_core.output_parsers import StrOutputParserfrom langchain_core.prompts import PromptTemplatefrom langchain_core.runnables import RunnablePassthrough, RunnableParallelembedding_model_name = 'D:\LLM\\bce_modesl\\bce-embedding-base_v1' embedding_model_kwargs = {'device' : 'cuda:0' } embedding_encode_kwargs = {'batch_size' : 32 , 'normalize_embeddings' : True , } embed_model = HuggingFaceEmbeddings( model_name=embedding_model_name, model_kwargs=embedding_model_kwargs, encode_kwargs=embedding_encode_kwargs ) if __name__ == '__main__' : path = "./test" text_loader_kwargs = {'autodetect_encoding' : True } loader = DirectoryLoader(path, glob="**/*.txt" , loader_cls=TextLoader, loader_kwargs=text_loader_kwargs, show_progress=True ) docs = loader.load() pass text_splitter = RecursiveCharacterTextSplitter( chunk_size=500 , chunk_overlap=0 , length_function=len , ) doc_list = [] owner_one_doc = docs[0 ] owner_one_docs = text_splitter.create_documents([owner_one_doc.page_content]) for i, doc in enumerate (owner_one_docs): doc.metadata["author" ] = ["userid_001" ] doc_list.append(doc) owner_two_doc = docs[1 ] owner_two_docs = text_splitter.create_documents([owner_two_doc.page_content]) for i, doc in enumerate (owner_two_docs): doc.metadata["author" ] = ["userid_022" ] doc_list.append(doc) vectorstore = ElasticsearchStore( es_url=os.environ['ELASTIC_HOST_HTTP' ], index_name="index_sd_1024_vectors" , embedding=embed_model, es_user="elastic" , vector_query_field='question_vectors' , es_password=os.environ['ELASTIC_ACCESS_PASSWORD' ] ) retriever = vectorstore.as_retriever() template = """使用下面的资料中的内容回答问题,如果没有资料,就回答:资料不全,无法回答您的问题。 参考资料: {context} 用户问题: {question} 你的回答:""" custom_rag_prompt = PromptTemplate.from_template(template) os.environ["QIANFAN_ACCESS_KEY" ] = os.getenv('MY_QIANFAN_ACCESS_KEY' ) os.environ["QIANFAN_SECRET_KEY" ] = os.getenv('MY_QIANFAN_SECRET_KEY' ) chat = QianfanChatEndpoint(model="ERNIE-Bot-4" ) def format_docs (docs ): return "\n\n" .join(doc.page_content for doc in docs) user_id = "userid_002" filter_criteria = [{"term" : {"metadata.author.keyword" : user_id}}] special_retriever = vectorstore.as_retriever(search_kwargs={'filter' : filter_criteria}) test_chain = RunnableParallel( {"context" : special_retriever, "question" : RunnablePassthrough()} ) rag_chain = ( {"context" : special_retriever | format_docs, "question" : RunnablePassthrough()} | custom_rag_prompt | chat | StrOutputParser() ) go_on = True while go_on: query_text = input ("你的问题: " ) if 'exit' in query_text: break print ("AI需要回答的问题 [{}]\n" .format (query_text)) docs = vectorstore.similarity_search(query_text) print (docs) docs = vectorstore.similarity_search( query_text, filter =[{"term" : {"metadata.author.keyword" : user_id}}] ) if len (docs) != 0 : print (docs[0 ].metadata) else : print ("没找到文档!" ) res = rag_chain.invoke(query_text) print (res) pass
输出引文
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 import jsonimport osimport refrom operator import itemgetterfrom langchain_community.chat_models import AzureChatOpenAIfrom langchain_community.embeddings import QianfanEmbeddingsEndpoint, HuggingFaceEmbeddingsfrom langchain_community.vectorstores.elasticsearch import ElasticsearchStorefrom langchain_core.prompts import ChatPromptTemplatefrom typing import List from langchain_core.documents import Documentfrom langchain_core.output_parsers import StrOutputParserfrom langchain_core.runnables import ( RunnableLambda, RunnableParallel, RunnablePassthrough, ) embedding_model_name = 'D:\LLM\\bce_modesl\\bce-embedding-base_v1' embedding_model_kwargs = {'device' : 'cuda:0' } embedding_encode_kwargs = {'batch_size' : 32 , 'normalize_embeddings' : True , } embed_model = HuggingFaceEmbeddings( model_name=embedding_model_name, model_kwargs=embedding_model_kwargs, encode_kwargs=embedding_encode_kwargs ) def parse_response_to_json (text ): pre_answer_match = re.search(r'^(.*?)(?=<cited_answer>)' , text, re.DOTALL) pre_answer_text = pre_answer_match.group(1 ).strip() if pre_answer_match else None cited_answer_match = re.search(r'<cited_answer>(.*?)<\/cited_answer>' , text, re.DOTALL) cited_answer_text = cited_answer_match.group(1 ).strip() if cited_answer_match else None output_json = { "response" : pre_answer_text, "cited_answer" : None } if cited_answer_text: answer_match = re.search(r'<answer>(.*?)<\/answer>' , cited_answer_text) citations_match = re.findall( r'<citation>\s*<source_id>(.*?)<\/source_id>\s*<quote>(.*?)<\/quote>\s*<\/citation>' , cited_answer_text, re.DOTALL) cited_answer_part = { "answer" : answer_match.group(1 ).strip() if answer_match else None , "citations" : [] } for source_id, quote in citations_match: cited_answer_part["citations" ].append({ "source_id" : source_id.strip(), "quote" : quote.strip() }) output_json["cited_answer" ] = cited_answer_part return json.dumps(output_json, ensure_ascii=False , indent=4 ) if __name__ == '__main__' : vectorstore = ElasticsearchStore( es_url=os.environ['ELASTIC_HOST_HTTP' ], index_name="index_sd_1024_vectors" , embedding=embed_model, es_user="elastic" , vector_query_field='question_vectors' , es_password=os.environ['ELASTIC_ACCESS_PASSWORD' ] ) retriever = vectorstore.as_retriever() system = """You're a helpful AI assistant. Given a user question and some document snippets, \ answer the user question and provide citations. If none of the articles answer the question, just say you don't know. Remember, you must return both an answer and citations. A citation consists of a VERBATIM quote that \ justifies the answer and the ID of the quote article. Return a citation for every quote across all articles \ that justify the answer. Use the following format for your final output: <cited_answer> <answer></answer> <citations> <citation><source_id></source_id><quote></quote></citation> <citation><source_id></source_id><quote></quote></citation> ... </citations> </cited_answer> Here are the document:{context}""" prompt = ChatPromptTemplate.from_messages( [("system" , system), ("human" , "{question}" )] ) os.environ["AZURE_OPENAI_API_KEY" ] = os.getenv('MY_AZURE_OPENAI_API_KEY' ) os.environ["AZURE_OPENAI_ENDPOINT" ] = os.getenv('MY_AZURE_OPENAI_ENDPOINT' ) DEPLOYMENT_NAME_GPT3P5 = os.getenv('MY_DEPLOYMENT_NAME_GPT3P5' ) chat = AzureChatOpenAI( openai_api_version="2023-05-15" , azure_deployment=DEPLOYMENT_NAME_GPT3P5, temperature=0 ) def format_docs (docs: List [Document] ) -> str : formatted = [] for i, doc in enumerate (docs): doc_str = f"""\ <source id=\"{i} \"> <article_snippet>{doc.page_content} </article_snippet> </source>""" formatted.append(doc_str) final_text = "\n\n<sources>" + "\n" .join(formatted) + "</sources>" return final_text format = itemgetter("docs" ) | RunnableLambda(format_docs) answer = prompt | chat | StrOutputParser() chain = ( RunnableParallel(question=RunnablePassthrough(), docs=retriever) .assign(context=format ) .assign(cited_answer=answer) .pick(["cited_answer" , "docs" ]) ) res = chain.invoke("谁从来不被技术分析师的预测所左右?" ) ai_res = res['cited_answer' ] json_obj_str = parse_response_to_json(ai_res) print (res) json_obj_obj = json.loads(json_obj_str) print (json_obj_obj) pass go_on = True while go_on: query_text = input ("你的问题: " ) if 'exit' in query_text: break print ("AI需要回答的问题 [{}]\n" .format (query_text)) res = chain.invoke(query_text) print (res)
Langchain系列[17]基于用户的搜索 + 添加引文信息
转载前请阅读本站 版权协议 ,文章著作权归 粥余 所有,转载请注明出处。