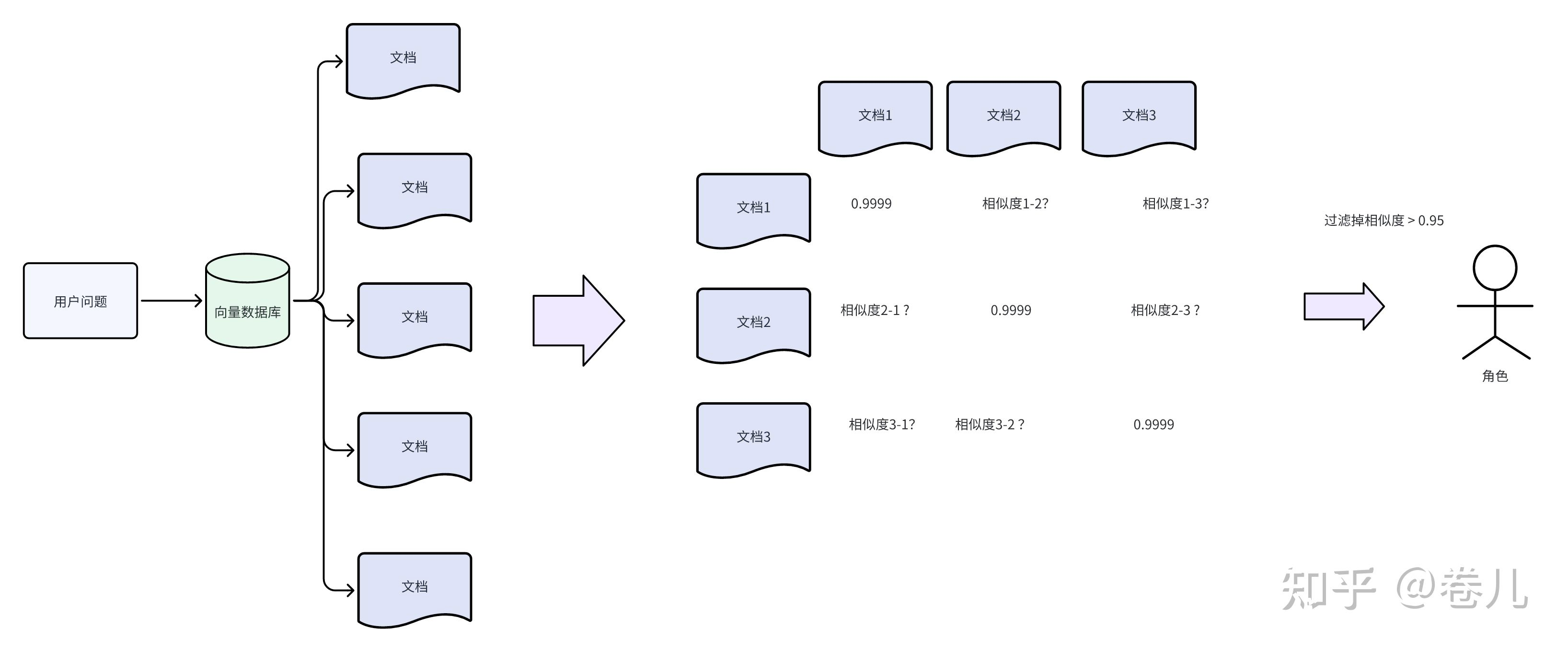
向量过滤 EmbeddingsFilter
使用大型语言模型(LLM)来处理每个找到的文件很费钱,而且速度不快。
而EmbeddingsFilter这个工具提供了一种更经济、更迅速的方法。
它会先将文件和你的问题转换成一种数学表达(嵌入),然后只挑出那些和你的问题在数学表达上相似的文件 。这样就不需要每个文件都去麻烦那个大模型,省时省力。
设定一个门限值,通过输入问题和内容的相关度(0~1),进行过滤
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 question = "What is Task Decomposition ?" loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/" ) docs = loader.load() text_splitter = RecursiveCharacterTextSplitter(chunk_size=400 ) docs = text_splitter.split_documents(docs) embedding_filter_embeddings_filter = EmbeddingsFilter(embeddings=embeddings_model, similarity_threshold=0.7 ) filtered_docs = embedding_filter_embeddings_filter.compress_documents(docs[:10 ],question) pass embedding_filter_compression_retriever = ContextualCompressionRetriever( base_compressor=embedding_filter_embeddings_filter, base_retriever=retriever ) embedding_filter_docs = embedding_filter_compression_retriever.get_relevant_documents(question) pass
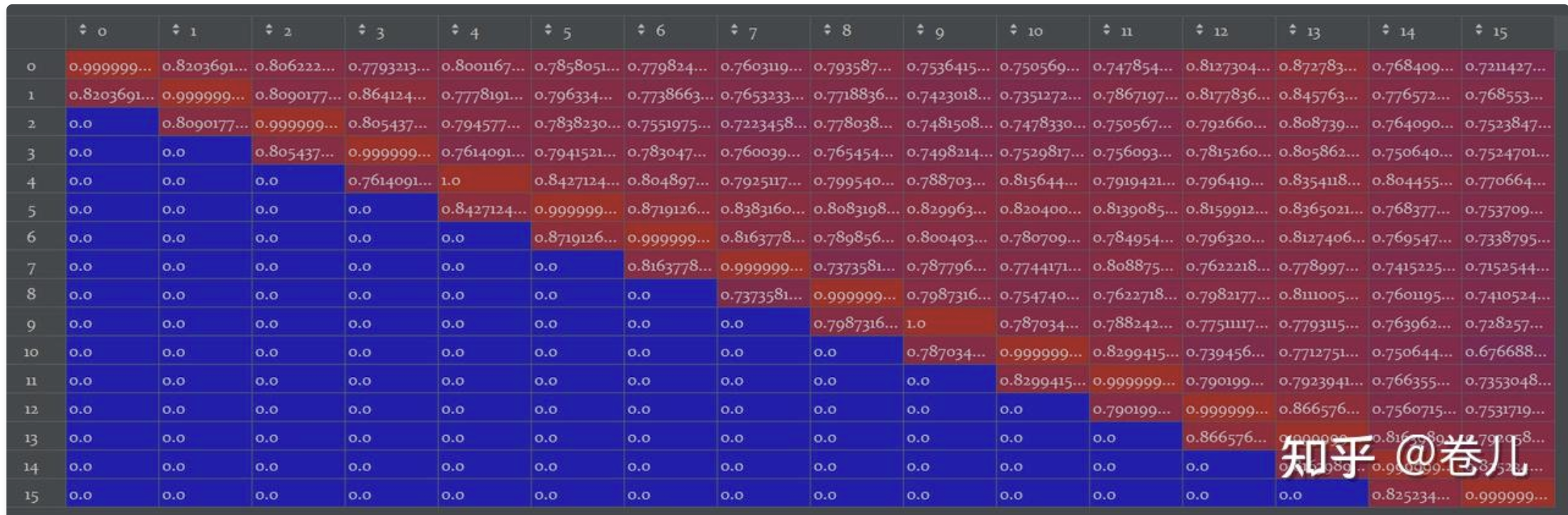
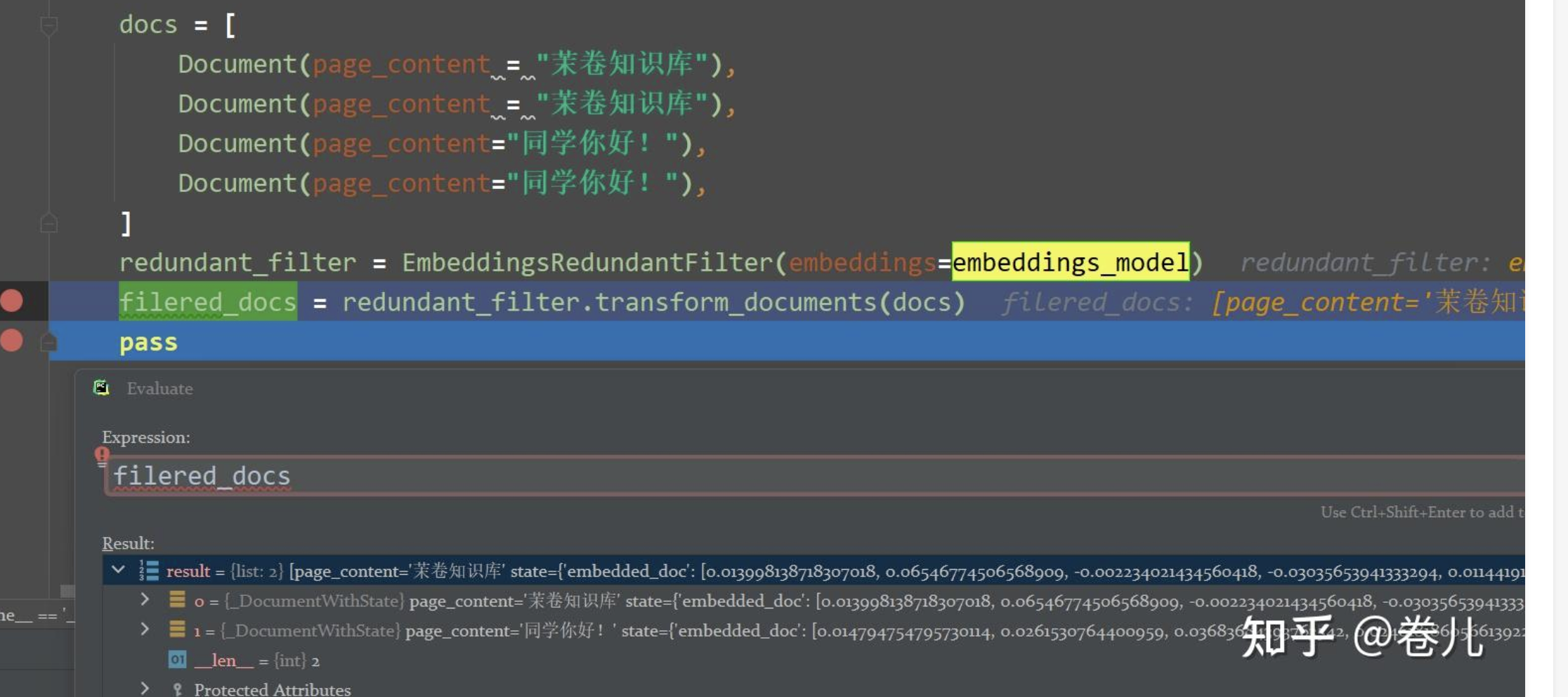
文档去重 EmbeddingsRedundantFilter
相似度矩阵右上部分:相似度阈值:similarity_threshold**:** float = 0.95
使用方法
1 2 3 4 5 6 7 8 docs = [ Document(page_content = "粥余知识库" ), Document(page_content = "粥余知识库" ), Document(page_content="同学你好!" ), Document(page_content="同学你好!" ), ] redundant_filter = EmbeddingsRedundantFilter(embeddings=embeddings_model) filered_docs = redundant_filter.transform_documents(docs)
文档一条龙处理:DocumentCompressorPipeline
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 redundant_filter = EmbeddingsRedundantFilter(embeddings=embeddings_model) emb_filter = EmbeddingsFilter(embeddings=embeddings_model, similarity_threshold=0.6 ) qianfan_compressor = LLMChainExtractor.from_llm(qianfan_chat) pipeline_compressor = DocumentCompressorPipeline( transformers=[emb_filter,redundant_filter,qianfan_compressor] ) compression_retriever = ContextualCompressionRetriever( base_compressor=pipeline_compressor, base_retriever=retriever ) compressed_docs = compression_retriever.get_relevant_documents(question)
Long-Context Reorder: 多个文档→重新排序
相关论文https://arxiv.org/abs/2307.03172
调用方法
1 2 3 4 5 6 7 retriever = vectorstore.as_retriever(search_kwargs={"k" : 10 }) docs_pre = retriever.get_relevant_documents('Decomposition' ) reordering = LongContextReorder() reordered_docs = reordering.transform_documents(docs_pre)
排序之前
排序之后
长文本注意事项
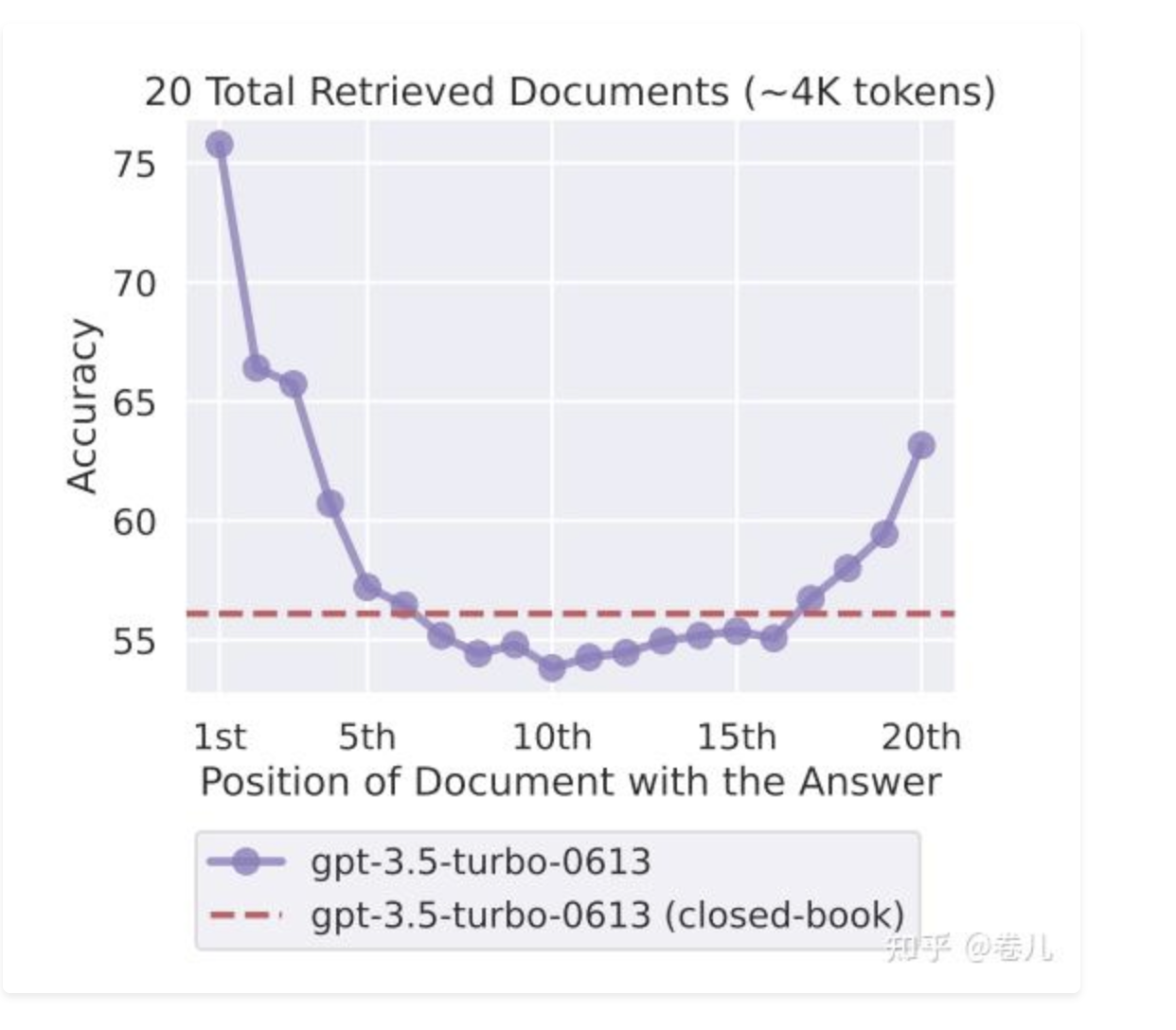
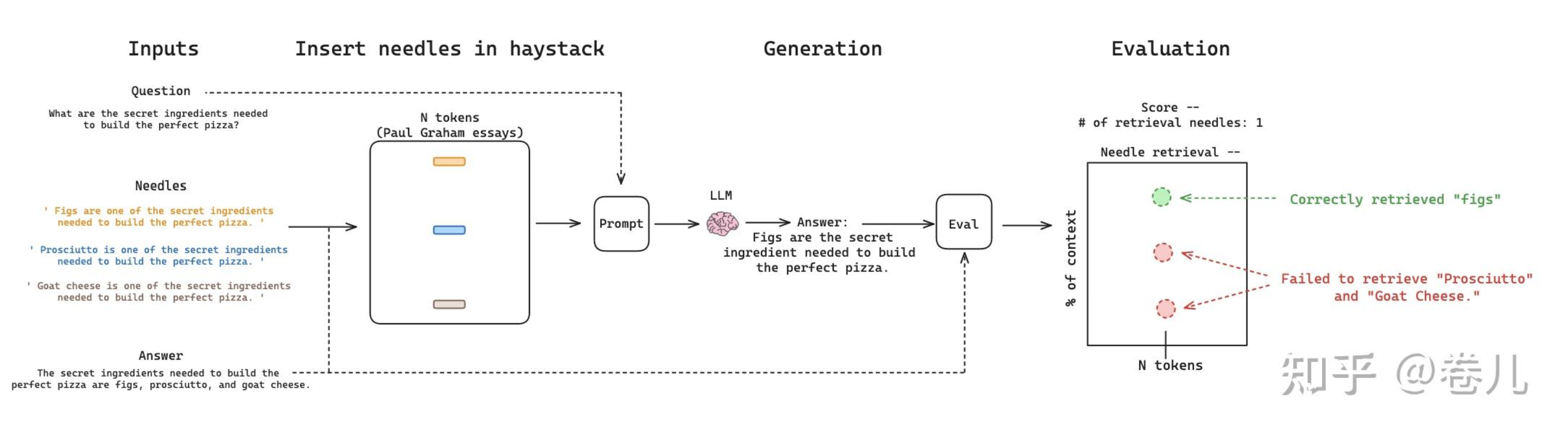
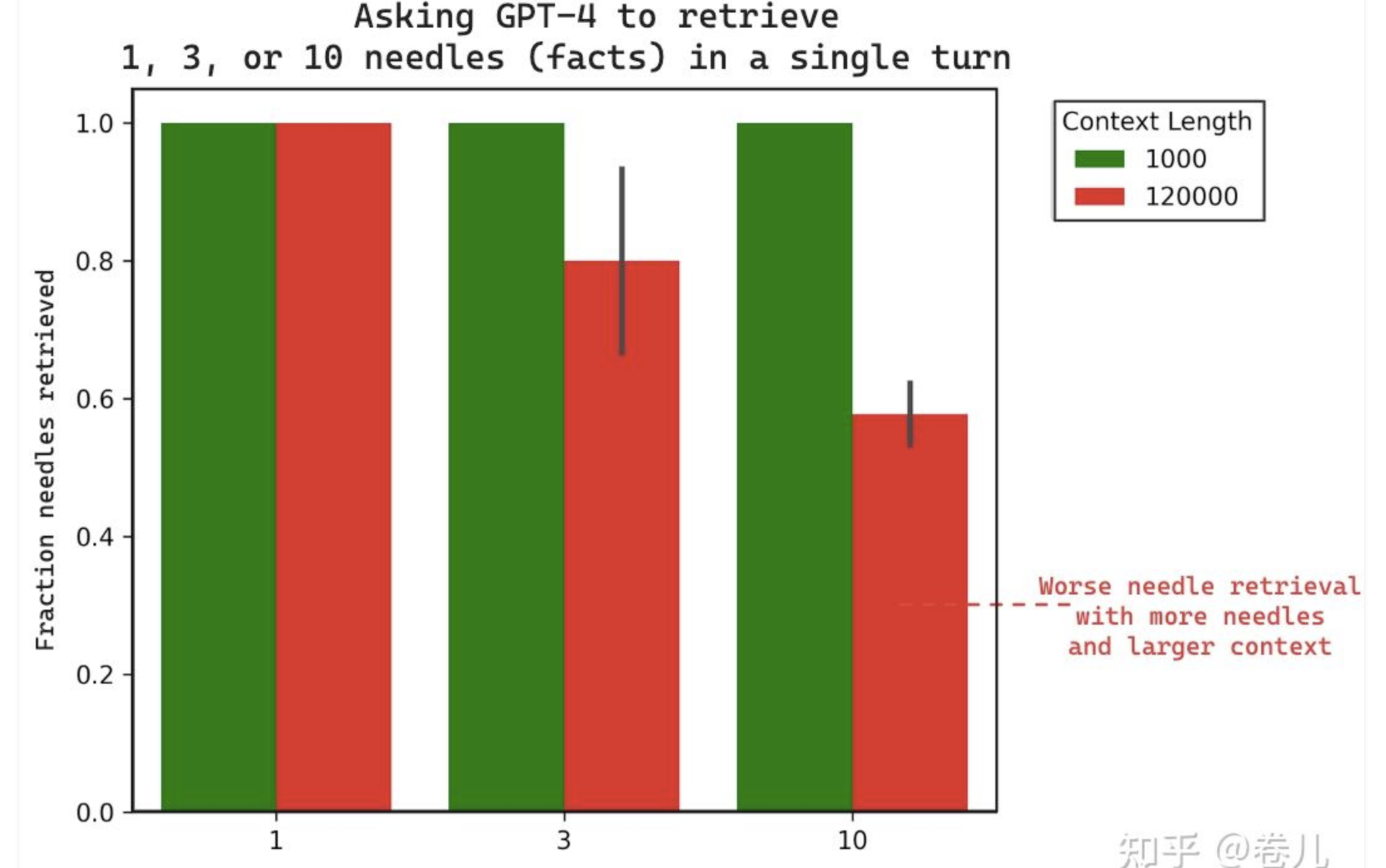
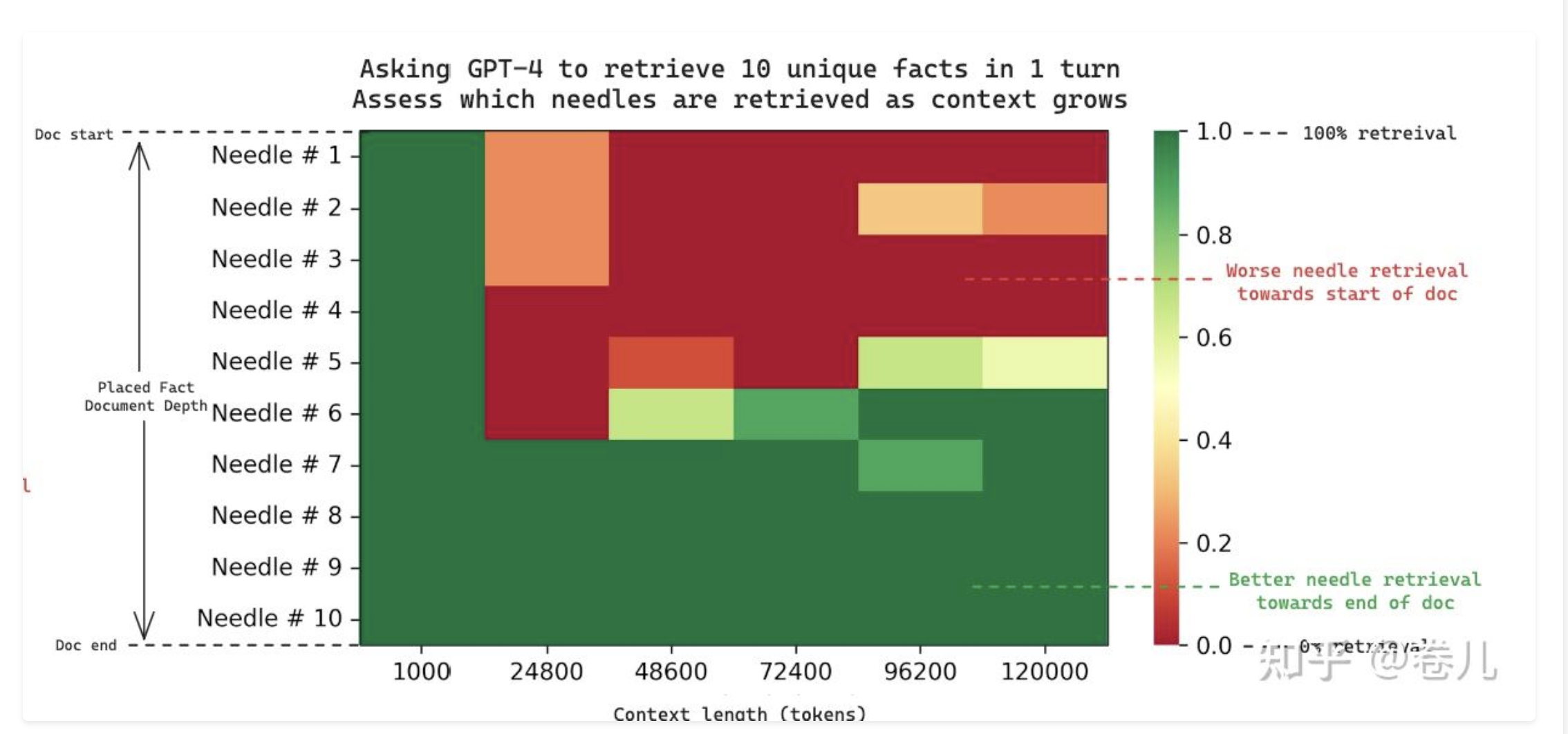
https://blog.langchain.dev/multi-needle-in-a-haystack/
在长文本提示词中(甚至长达1MB),将事实 放到不同的位置,召回效果不同
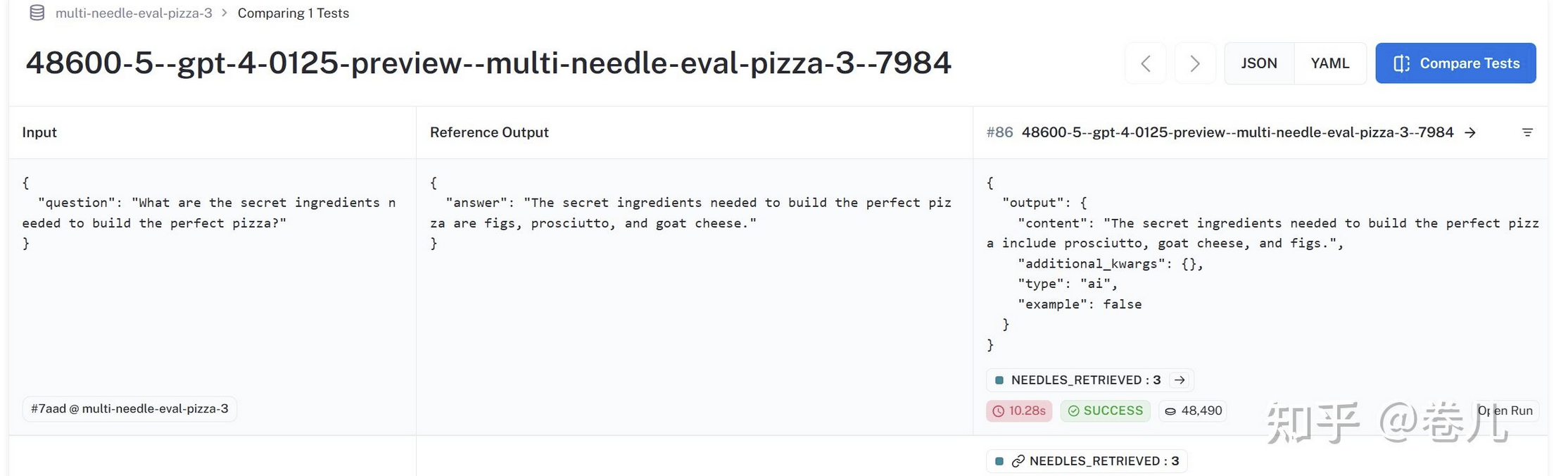
正确的召回
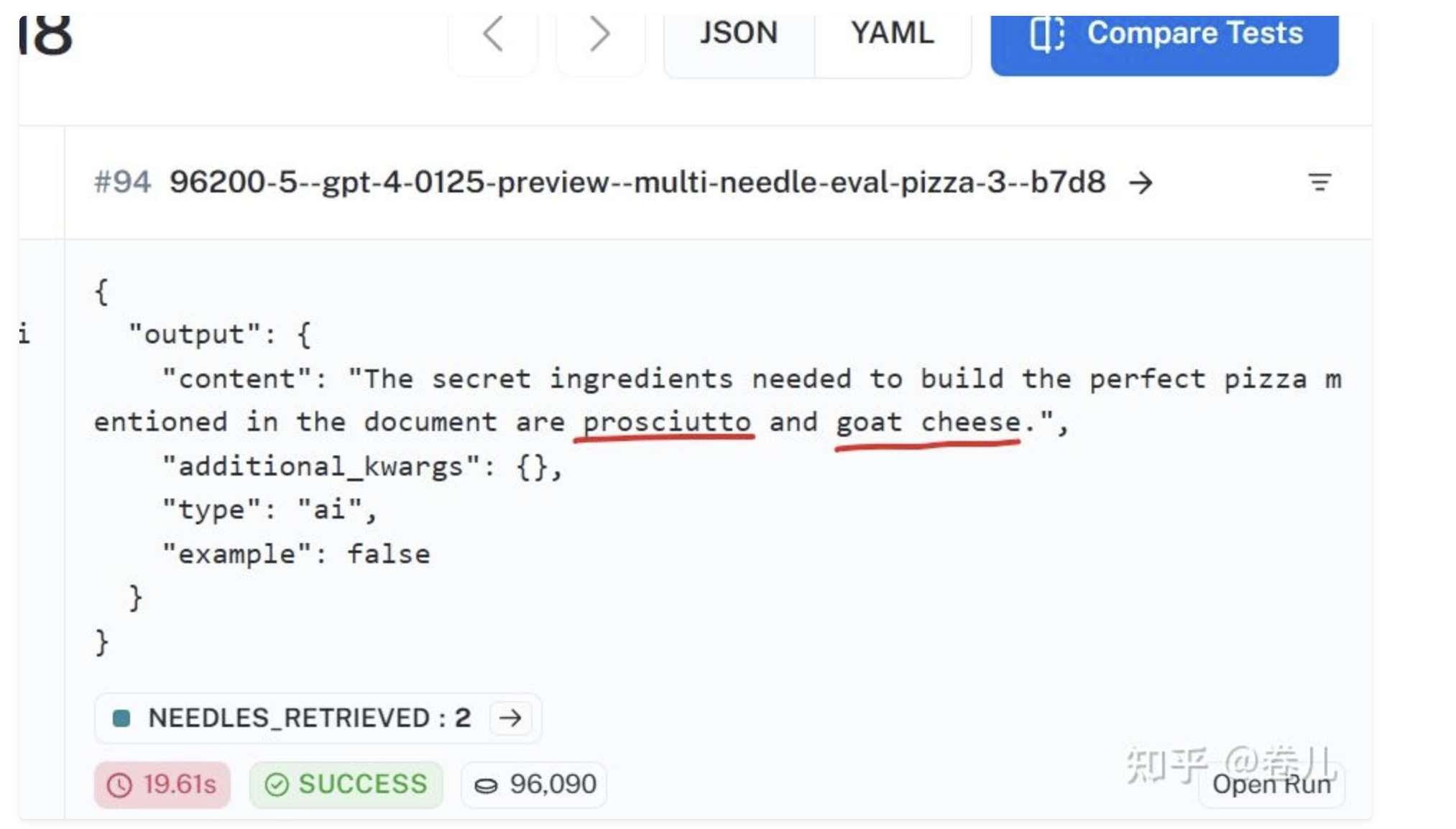
不完整的召回
事实 处于不同的文档深度时
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 from uuid import uuid4from langchain.retrievers import ContextualCompressionRetrieverfrom langchain.retrievers.document_compressors import LLMChainExtractor, LLMChainFilter, EmbeddingsFilter, \ DocumentCompressorPipeline from langchain.text_splitter import CharacterTextSplitterfrom langchain_community.chat_models import AzureChatOpenAIfrom langchain_community.chat_models.baidu_qianfan_endpoint import QianfanChatEndpointfrom langchain_community.document_loaders.web_base import WebBaseLoaderfrom langchain_community.document_transformers import EmbeddingsRedundantFilter, LongContextReorderfrom langchain_community.llms.chatglm3 import ChatGLM3from langchain_community.vectorstores.elasticsearch import ElasticsearchStoreimport osfrom langchain_community.embeddings import QianfanEmbeddingsEndpoint, HuggingFaceEmbeddingsfrom langchain_core.documents import Documentfrom langchain_core.messages import SystemMessagefrom langchain_core.output_parsers import StrOutputParserfrom langchain_core.prompts import ChatPromptTemplatefrom langchain_text_splitters import RecursiveCharacterTextSplitterfrom zhipuai import ZhipuAIunique_id = uuid4().hex [0 :8 ] os.environ["LANGCHAIN_PROJECT" ] = f" 文档处理管道 Walkthrough - {unique_id} " os.environ["LANGCHAIN_TRACING_V2" ] = 'true' os.environ["LANGCHAIN_API_KEY" ] = os.getenv('MY_LANGCHAIN_API_KEY' ) bge_en_v1p5_model_path = "D:\\LLM\\Bge_models\\bge-base-en-v1.5" embeddings_model = HuggingFaceEmbeddings( model_name=bge_en_v1p5_model_path, model_kwargs={'device' : 'cuda:0' }, encode_kwargs={'batch_size' : 32 , 'normalize_embeddings' : True , } ) vectorstore = ElasticsearchStore( es_url=os.environ['ELASTIC_HOST_HTTP' ], index_name="index_sd_1024_vectors" , embedding=embeddings_model, es_user="elastic" , vector_query_field='question_vectors' , es_password=os.environ['ELASTIC_ACCESS_PASSWORD' ] ) retriever = vectorstore.as_retriever(search_kwargs={"k" : 4 }) os.environ["AZURE_OPENAI_API_KEY" ] = os.getenv('MY_AZURE_OPENAI_API_KEY' ) os.environ["AZURE_OPENAI_ENDPOINT" ] = os.getenv('MY_AZURE_OPENAI_ENDPOINT' ) DEPLOYMENT_NAME_GPT3P5 = os.getenv('MY_DEPLOYMENT_NAME_GPT3P5' ) azure_chat = AzureChatOpenAI( openai_api_version="2023-05-15" , azure_deployment=DEPLOYMENT_NAME_GPT3P5, temperature=0 ) os.environ["QIANFAN_ACCESS_KEY" ] = os.getenv('MY_QIANFAN_ACCESS_KEY' ) os.environ["QIANFAN_SECRET_KEY" ] = os.getenv('MY_QIANFAN_SECRET_KEY' ) qianfan_chat = QianfanChatEndpoint( model="ERNIE-Bot-4" ) messages = [ SystemMessage(content="You are an intelligent AI assistant, named ChatGLM3." ), ] LOCAL_GLM3_6B_ENDPOINT = "http://127.0.0.1:8000/v1/chat/completions" local_glm3_chat = ChatGLM3( endpoint_url=LOCAL_GLM3_6B_ENDPOINT, max_tokens=(1024 * 32 ), prefix_messages=messages, top_p=0.9 , temperature=0 , stream=True , ) if __name__ == '__main__' : question = "What is Task Decomposition ?" loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/" ) docs = loader.load() text_splitter = RecursiveCharacterTextSplitter(chunk_size=400 ) docs = text_splitter.split_documents(docs) embedding_filter_embeddings_filter = EmbeddingsFilter(embeddings=embeddings_model, similarity_threshold=0.7 ) filtered_docs = embedding_filter_embeddings_filter.compress_documents(docs[:10 ],question) pass embedding_filter_compression_retriever = ContextualCompressionRetriever( base_compressor=embedding_filter_embeddings_filter, base_retriever=retriever ) docs = [ Document(page_content = "粥余知识库" ), Document(page_content = "粥余知识库" ), Document(page_content="同学你好!" ), Document(page_content="同学你好!" ), ] redundant_filter = EmbeddingsRedundantFilter(embeddings=embeddings_model) relevant_filter = EmbeddingsFilter(embeddings=embeddings_model, similarity_threshold=0.6 ) qianfan_compressor = LLMChainExtractor.from_llm(qianfan_chat) pipeline_compressor = DocumentCompressorPipeline( transformers=[redundant_filter, relevant_filter,qianfan_compressor] ) compression_retriever = ContextualCompressionRetriever( base_compressor=pipeline_compressor, base_retriever=retriever ) pass retriever = vectorstore.as_retriever(search_kwargs={"k" : 10 }) docs_pre = retriever.get_relevant_documents('Decomposition' ) reordering = LongContextReorder() reordered_docs = reordering.transform_documents(docs_pre) pass
Langchain系列[15]向量过滤 VS 文档去重
转载前请阅读本站 版权协议 ,文章著作权归 粥余 所有,转载请注明出处。