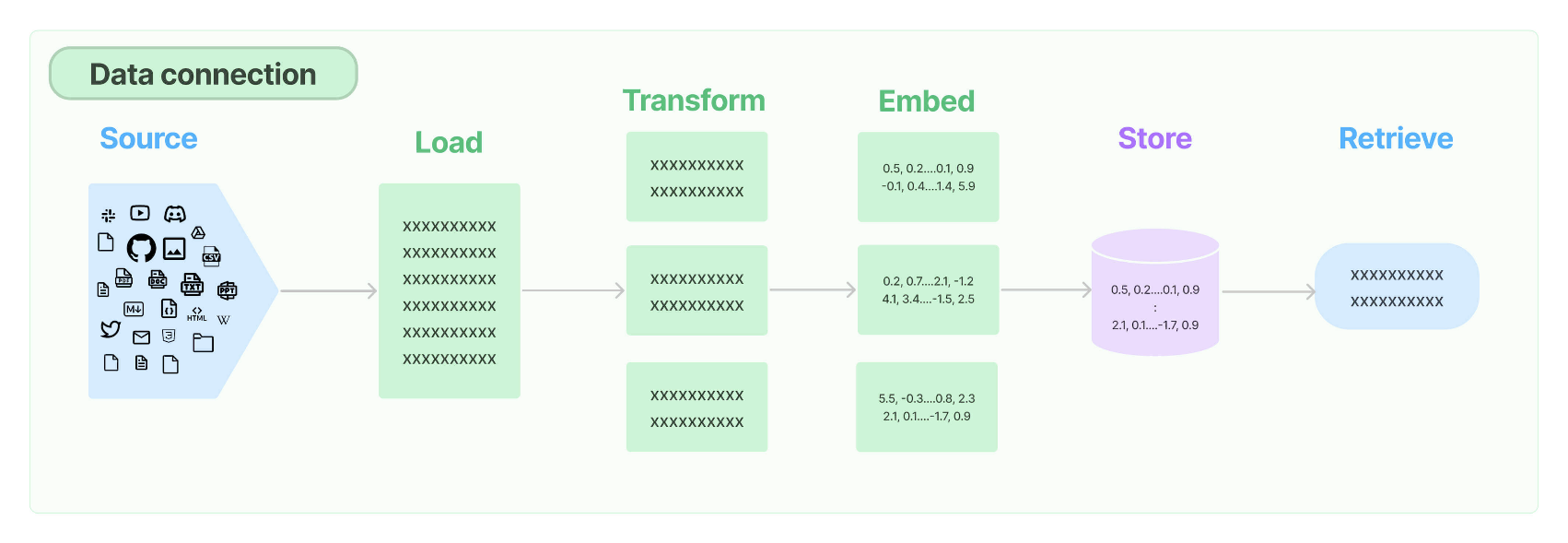
目标 了解向量数据库的作用,能够使用本地向量数据库Chroma 和 云端的 Elastic Search
向量搜索 是一种常见的存储和搜索非结构化数据(如非结构化文本)的方法。其思想是存储与文本相关的数值向量。给定一个查询,我们可以将其嵌入为相同维度的向量,并使用向量相似性度量来识别存储中的相关数据。
LangChain VectorStore 对象包含用于将 文本和 Document
LangChain 包含了一套与不同向量存储技术集成的工具。一些向量存储由提供商托管(例如,各种云服务提供商),使用时需要特定的凭据;
另一些(如 Postgres)在独立的基础设施中运行,可以本地运行或通过第三方运行;还有一些可以内存运行,用于轻量级工作负载。
文档 Documents 在正式进入主题之前,我们需要介绍一下langchain中对于文档的抽象Documents。
LangChain 实现了一个 Document 抽象,旨在表示文本单元和相关元数据。它有两个属性:
page_content:表示内容的字符串metadata:包含任意元数据的字典
元数据属性可以捕获有关文档来源的信息、与其他文档的关系以及其他信息。
请注意,一个单独的 Document 对象通常代表了一个更大文档的一部分
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 from langchain_core.documents import Documentdocuments = [ Document( page_content="Dogs are great companions, known for their loyalty and friendliness." , metadata={"source" : "mammal-pets-doc" }, ), Document( page_content="Cats are independent pets that often enjoy their own space." , metadata={"source" : "mammal-pets-doc" }, ), Document( page_content="Goldfish are popular pets for beginners, requiring relatively simple care." , metadata={"source" : "fish-pets-doc" }, ), Document( page_content="Parrots are intelligent birds capable of mimicking human speech." , metadata={"source" : "bird-pets-doc" }, ), Document( page_content="Rabbits are social animals that need plenty of space to hop around." , metadata={"source" : "mammal-pets-doc" }, ), ]
Chroma 传送门
Chroma 是一个可以在本地运行的向量数据库。通过langchain 在本地建立一个数据库:
persist_directory : chroma 数据库保存路径
embeddings_model :一个嵌入模型,可以是本地模型,可以是云端的模型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 from langchain_core.documents import Documentdocuments = [ Document( page_content="Dogs are great companions, known for their loyalty and friendliness." , metadata={"source" : "mammal-pets-doc" }, ), Document( page_content="Cats are independent pets that often enjoy their own space." , metadata={"source" : "mammal-pets-doc" }, ), ] os.environ["QIANFAN_AK" ] = MY_QIANFAN_AK os.environ["QIANFAN_SK" ] = MY_QIANFAN_SK embeddings_model = QianfanEmbeddingsEndpoint(model="bge_large_en" , endpoint="bge_large_en" ) vector_store = Chroma(persist_directory="D:\\LLM\\my_projects\\chroma_db" , embedding_function=embeddings_model) vector_store.add_documents(documents) query = 'Dogs?' docs = vector_store.similarity_search(query) pass query_vctor = embeddingsa_model.embed_query(query) docs = vector_store.similarity_search_by_vector(query_vctor) print (docs[0 ].page_content)pass retriever = vector_store.as_retriever() res = retriever.invoke(query) pass
Elastic Search 高性能 +可视化 Dashboard + more …
支持本地 和云端 部署 (阿里云和百度云有相关服务)
安装
1 pip install elasticsearch
ELASTIC_HOST_HTTP:服务端地址
ELASTIC_ACCESS_PASSWORD:密码
index_name:数据所在的索引
es_user:用户名
embedding:嵌入模型
vector_query_field: 向量变量的名称
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 vectorstore = ElasticsearchStore( es_url=os.environ['ELASTIC_HOST_HTTP' ], index_name="index_sd_1024_vectors" , embedding=embeddings_model, es_user="elastic" , vector_query_field='question_vectors' , es_password=os.environ['ELASTIC_ACCESS_PASSWORD' ] ) docs = [Document(page_content ='Mojuan Test ES ..' ), Document(page_content='Susirial is a teacher' )] vectorstore.add_documents(docs) q_docs = vectorstore.similarity_search('Who is Susiral' )
Elasticsearch 支持以下向量距离相似性算法:
余弦相似度(cosine):这是默认的相似性算法,它测量两个向量在角度空间上的相似度,范围从-1(完全不同)到1(完全相同)。余弦相似度不考虑向量的大小,只考虑它们的方向,因此它对于高维空间中的文本数据特别有用。
欧几里得距离(euclidean):这是一种测量两个向量在欧几里得空间中的直线距离的算法。欧几里得距离越小,表示两个向量越相似。与余弦相似度不同,欧几里得距离考虑了向量的大小和方向。
点积(dot_product):这是一种基于向量点积的相似性度量方法。点积越大,表示两个向量越相似。点积实际上是一种特殊的余弦相似度,它假设向量已经被归一化(即长度为1)。 在 Elasticsearch 中,您可以通过设置 similarity 参数来指定所需的相似性算法。例如,当创建索引时,您可以指定使用哪种算法来计算向量之间的相似度。这允许您根据数据的特性和应用的需求选择最合适的相似性度量方法。
Elasticsearch 使用了许多信息检索技术,包括 BM25 算法和倒排索引 。
倒排索引 : Elasticsearch 使用倒排索引来存储文档中的词和它们所在的文档。每个词都与包含该词的所有文档的列表相关联 。这样,Elasticsearch 可以快速地找到包含特定词的所有文档,而不需要检查每个文档。BM25 算法 : Elasticsearch 默认使用 BM25 算法来计算文档与查询之间的相关性 。BM25 考虑了文档的词频 (TF)、文档的倒数文档频率 (IDF)以及文档长度 等因素,来评估文档与查询的相关性。Elasticsearch 使用 BM25 算法来对搜索结果进行排序,返回与查询最相关的文档。 除了 BM25 算法和倒排索引,Elasticsearch 还使用了许多其他的信息检索技术,例如词干提取(Stemming)、词形还原(Lemmatization)、布尔查询(Boolean queries)等,以提供高效的搜索引擎功能。
如果你对ES非常熟悉,你可以直接调用Langchain 里面的elasticsearch实例
比如:普通字符串搜索
query_dict: 是一个Elastic Search 支持的搜索格式
1 2 3 4 5 6 7 8 9 query = 'Susirial' query_dict = {"query" : {"match" : {"text" : query}}} res = vectorstore.client.search(index='index_sd_1024_vectors' , body=query_dict) docs = [] for r in res["hits" ]["hits" ]: docs.append(Document(page_content=r['_source' ]['text' ])) print ('找到: {}' .format (r['_source' ]['text' ])) pass
向量搜索 + BM25 = 提高文档召回率
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 import osimport numpy as npfrom langchain_community.embeddings import HuggingFaceEmbeddings, QianfanEmbeddingsEndpointfrom langchain_community.retrievers import ElasticSearchBM25Retrieverfrom langchain_community.vectorstores.chroma import Chromafrom langchain_community.vectorstores.elasticsearch import ElasticsearchStorefrom langchain_core.documents import Documentdef cosine_similarity (vec1, vec2 ): dot_product = np.dot(vec1, vec2) norm_vec1 = np.linalg.norm(vec1) norm_vec2 = np.linalg.norm(vec2) return dot_product / (norm_vec1 * norm_vec2) if __name__ == '__main__' : os.environ["QIANFAN_AK" ] = MY_QIANFAN_AK os.environ["QIANFAN_SK" ] = MY_QIANFAN_SK embeddings_model = QianfanEmbeddingsEndpoint(model="bge_large_en" , endpoint="bge_large_en" ) vector_store = Chroma(persist_directory="D:\\LLM\\my_projects\\chroma_db" , embedding_function=embeddings_model) query = 'how can langsmith help with testing?' docs = vector_store.similarity_search(query) pass query_vctor = embeddings_model.embed_query(query) docs = vector_store.similarity_search_by_vector(query_vctor) print (docs[0 ].page_content) pass retriever = vector_store.as_retriever() res = retriever.invoke(query) pass vectorstore = ElasticsearchStore( es_url=os.environ['ELASTIC_HOST_HTTP' ], index_name="index_sd_1024_vectors" , embedding=embeddings_model, es_user="elastic" , vector_query_field='question_vectors' , es_password=os.environ['ELASTIC_ACCESS_PASSWORD' ] ) docs = [Document(page_content ='Mojuan Test ES ..' ), Document(page_content='Susirial is a teacher' )] pass query = 'Susirial' query_dict = {"query" : {"match" : {"text" : query}}} res = vectorstore.client.search(index='index_sd_1024_vectors' , body=query_dict) docs = [] for r in res["hits" ]["hits" ]: docs.append(Document(page_content=r['_source' ]['text' ])) print ('找到: {}' .format (r['_source' ]['text' ])) pass