LLama2大模型量化部署
Llama模型量化模型cpp部署
部署步骤
wsl下部署没啥装个Ubuntu22.04先。
然后git clone两个项目。
首先是llama的git项目
1 | git clone https://github.com/facebookresearch/llama.git |
然后是cpp
1 | git clone https://github.com/ggerganov/llama.cpp.git |
然后进入llama的项目
1 | cd llama |
然后去官网https://ai.meta.com/resources/models-and-libraries/llama-downloads/
申请下载到邮箱
1 | ./download.sh |
然后就是这样子
等待模型下载完毕以后,进入llama.cpp
1 | cd llama.cpp |
先安装gcc环境
1 | sudo apt install build-essential |
编译等待编译完成
1 | make |
安装python依赖
1 | python3 -m pip install -r requirements.txt |
转换模型,当然还有其他参数我们可以直接打开convert.py去查看
1 | python3 convert.py '模型地址' |
那么如果遇到以下问题
1 | ```bash |
不要去相信网上的added_tokens.json
实际上在llama-2-7b-chat文件夹中,应该有一个.json文件(可能是params.json)。打开这个json文件,将”vocab_size”从-1改为32000。
注意
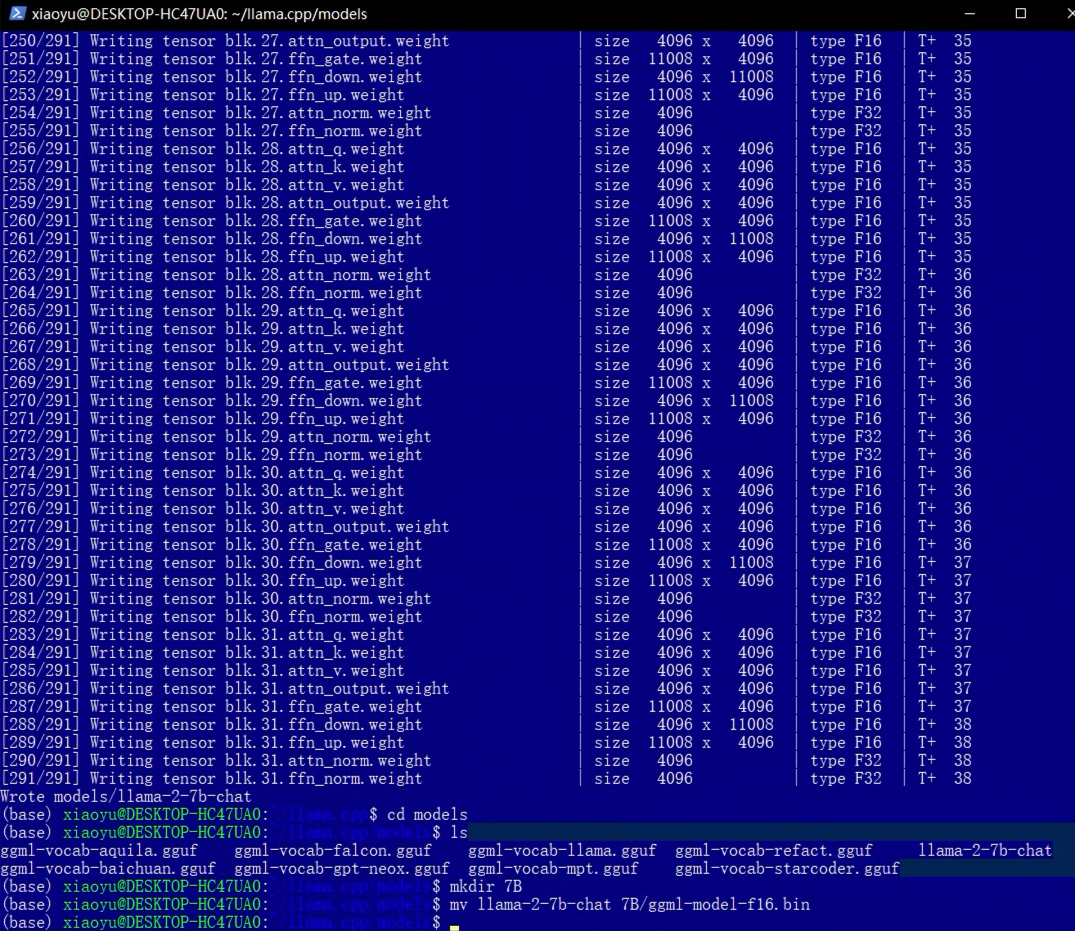
实际上最后输出的是一个.bin文件,所以我们上面的命令是有瑕疵的。
所以当我们转换成功以后。
1 | cd models |
量化
我们上面改为了bin这里也变成bin,我们执行的是4bit量化, 输出到./models/7B/目录下面
1 | ./quantize ./models/7B/ggml-model-f16.bin ./models/7B/ggml-model-q4_0.gguf q4_0 |
运行
1 | ./main -m ./models/7B/ggml-model-q4_0.gguf -n 256 --repeat_penalty 1.0 --color -i -r "User:" -f prompts/chat-with-bob.txt |


![Langchain系列[20]与SQL数据库进行聊天](/img/langchain/cover.png)